6.9并发设计模型研究
目录介绍
- 01.并发设计模式介绍
- 1.1 不可变解决并发
- 1.2 COW解决并发
- 1.3 线程本地存储模式
- 02.不变性模式解读
- 2.1 解决并发问题
- 2.2 实现不可变性的类
- 2.3 Java SDK不可变类
- 2.4 不可变修改操作
- 2.5 享元模式的优化
- 2.6 Immutability注意点
- 03.COW策略模式解读
- 3.1 为何有COW模式
- 3.2 COW应用场景
- 3.3 RPC框架应用COW分析
- 3.4 COW如何解决并发
- 3.5 COW内存消耗
- 3.6 COW为何没有LinkedList
- 04.线程本地存储解读
- 4.1 为何局部变量线程安全
- 4.2 理解线程本地存储
- 4.3 线程本地存储场景
- 4.4 ThreadLocal核心设计
- 4.5 ThreadLocal内存泄漏
- 4.6 ThreadLocal缺点
- 4.7 避免共享解决并发总结
01.并发设计模式介绍
1.1 不可变解决并发
1.2 COW解决并发
1.3 线程本地存储模式
02.不变性模式解读
2.1 解决并发问题
- 多线程并发问题
- “多个线程同时读写同一共享变量存在并发问题”,这里的必要条件之一是读写,如果只有读,而没有写,是没有并发问题的。
- 如何快速解决并发问题
- 最简单的办法就是让共享变量只有读操作,而没有写操作。这个办法如此重要,以至于被上升到了一种解决并发问题的设计模式:不变性(Immutability)模式。
- 所谓不变性,简单来讲,对象一旦被创建之后,状态就不再发生变化。换句话说,就是变量一旦被赋值,就不允许修改了(没有写操作);没有修改操作,也就是保持了不变性。
2.2 实现不可变性的类
- 实现一个具备不可变性的类。
- 将一个类所有的属性都设置成 final 的,并且只允许存在只读方法,那么这个类基本上就具备不可变性了。
- 更严格的做法是这个类本身也是 final 的,也就是不允许继承。因为子类可以覆盖父类的方法,有可能改变不可变性,所以推荐你在实际工作中,使用这种更严格的做法。
2.3 Java SDK不可变类
- SDK 里很多类都具备不可变性。
- 例如经常用到的 String 和 Long、Integer、Double 等基础类型的包装类都具备不可变性,这些对象的线程安全性都是靠不可变性来保证的。
- 如果你仔细翻看这些类的声明、属性和方法,你会发现它们都严格遵守不可变类的三点要求:类和属性都是 final 的,所有方法均是只读的。
- Java 的 String 方法也有类似字符替换操作,怎么能说所有方法都是只读的呢?
- 结合 String 的源代码来解释一下这个问题,下面的示例代码源自 Java 1.8 SDK,仅保留了关键属性 value[]和 replace() 方法
- 你会发现:String 这个类以及它的属性 value[]都是 final 的;而 replace() 方法的实现,就的确没有修改 value[],而是将替换后的字符串作为返回值返回了。
public final class String { private final char value[]; // 字符替换 String replace(char oldChar, char newChar) { //无需替换,直接返回this if (oldChar == newChar){ return this; } int len = value.length; int i = -1; /* avoid getfield opcode */ char[] val = value; //定位到需要替换的字符位置 while (++i < len) { if (val[i] == oldChar) { break; } } //未找到oldChar,无需替换 if (i >= len) { return this; } //创建一个buf[],这是关键 //用来保存替换后的字符串 char buf[] = new char[len]; for (int j = 0; j < i; j++) { buf[j] = val[j]; } while (i < len) { char c = val[i]; buf[i] = (c == oldChar) ? newChar : c; i++; } //创建一个新的字符串返回 //原字符串不会发生任何变化 return new String(buf, true); } } - 如果具备不可变性的类,需要提供类似修改的功能,具体该怎么操作呢?
- 做法很简单,那就是创建一个新的不可变对象,这是与可变对象的一个重要区别,可变对象往往是修改自己的属性。
- 所有的修改操作都创建一个新的不可变对象,你可能会有这种担心:是不是创建的对象太多了,有点太浪费内存呢?是的,这样做的确有些浪费,那如何解决呢?可以用享元模式
2.5 享元模式的优化
- 利用享元模式可以减少创建对象的数量,从而减少内存占用。
- Java 语言里面 Long、Integer、Short、Byte 等这些基本数据类型的包装类都用到了享元模式。
- 以 Long 这个类作为例子,看看它是如何利用享元模式来优化对象的创建的。
- 享元模式本质上其实就是一个对象池
- 利用享元模式创建对象的逻辑也很简单:创建之前,首先去对象池里看看是不是存在;如果已经存在,就利用对象池里的对象;如果不存在,就会新创建一个对象,并且把这个新创建出来的对象放进对象池里。
- Long 这个类并没有照搬享元模式
- Long 内部维护了一个静态的对象池,仅缓存了(-128,127)之间的数字,这个对象池在 JVM 启动的时候就创建好了,而且这个对象池一直都不会变化,也就是说它是静态的。
- 之所以采用这样的设计,是因为 Long 这个对象的状态共有 264 种,实在太多,不宜全部缓存,而(-128,127)之间的数字利用率最高。
2.6 Immutability注意点
- 在使用 Immutability 模式的时候,需要注意以下两点:
- 对象的所有属性都是 final 的,并不能保证不可变性;
- 不可变对象也需要正确发布。
- 在 Java 语言中,final 修饰的属性一旦被赋值,就不可以再修改,但是如果属性的类型是普通对象,那么这个普通对象的属性是可以被修改的。
- 例如下面的代码中,Bar 的属性 foo 虽然是 final 的,依然可以通过 setAge() 方法来设置 foo 的属性 age。
- 所以,在使用 Immutability 模式的时候一定要确认保持不变性的边界在哪里,是否要求属性对象也具备不可变性。
class Foo{ int age=0; int name="abc"; } final class Bar { final Foo foo; void setAge(int a){ foo.age=a; } }
03.COW策略模式解读
3.1 为何有COW模式
- 先来看一个案例,看看String类中replace方法
- Java 里 String 这个类在实现 replace() 方法的时候,并没有更改原字符串里面 value[]数组的内容,而是创建了一个新字符串,这种方法在解决不可变对象的修改问题时经常用到。
- 如果深入地思考这个方法,你会发现它本质上是一种 Copy-on-Write 方法。所谓 Copy-on-Write,经常被缩写为 COW 或者 CoW,顾名思义就是写时复制。
- 不可变对象的写操作往往都是使用 Copy-on-Write 方法解决的,当然 Copy-on-Write 的应用领域并不局限于 Immutability 模式。
3.2 COW应用场景
- 常见的Copy-on-Write模式应用
- CopyOnWriteArrayList 和 CopyOnWriteArraySet 这两个 Copy-on-Write 容器,它们背后的设计思想就是 Copy-on-Write;
- 通过 Copy-on-Write 这两个容器实现的读操作是无锁的,由于无锁,所以将读操作的性能发挥到了极致。
- Java 提供的 Copy-on-Write 容器,由于在修改的同时会复制整个容器,所以在提升读操作性能的同时,是以内存复制为代价的。
- Java中的Copy-on-Write 容器使用建议
- CopyOnWriteArrayList 和 CopyOnWriteArraySet 这两个 Copy-on-Write 容器在修改的时候会复制整个数组,如果容器经常被修改或者这个数组本身就非常大的时候,是不建议使用的。
- 反之,如果是修改非常少、数组数量也不大,并且对读性能要求苛刻的场景,使用 Copy-on-Write 容器效果就非常好了。
- Copy-on-Write 其实就是在操作系统领域
- Unix 的操作系统中创建进程的 API 是 fork(),传统的 fork() 函数会创建父进程的一个完整副本,例如父进程的地址空间现在用到了 1G 的内存,那么 fork() 子进程的时候要复制父进程整个进程的地址空间(占有 1G 内存)给子进程,这个过程是很耗时的。
- Linux 中的 fork() 函数就聪明得多,fork() 子进程的时候,并不复制整个进程的地址空间,而是让父子进程共享同一个地址空间;只用在父进程或者子进程需要写入的时候才会复制地址空间,从而使父子进程拥有各自的地址空间。
- 父子进程的地址空间以及数据都是要隔离的,使用 Copy-on-Write 更多地体现的是一种延时策略,只有在真正需要复制的时候才复制,而不是提前复制好,同时 Copy-on-Write 还支持按需复制,可以提升性能。
3.3 RPC框架应用COW分析
3.4 COW如何解决并发
3.5 COW内存消耗
3.6 COW为何没有LinkedList
04.线程本地存储解读
4.1 为何局部变量线程安全
- 两个线程可以同时用不同的参数调用相同的方法,那调用栈和线程之间是什么关系呢?
- 答案是:每个线程都有自己独立的调用栈。因为如果不是这样,那两个线程就互相干扰了。
- 如下面这幅图所示,线程 A、B、C 每个线程都有自己独立的调用栈。
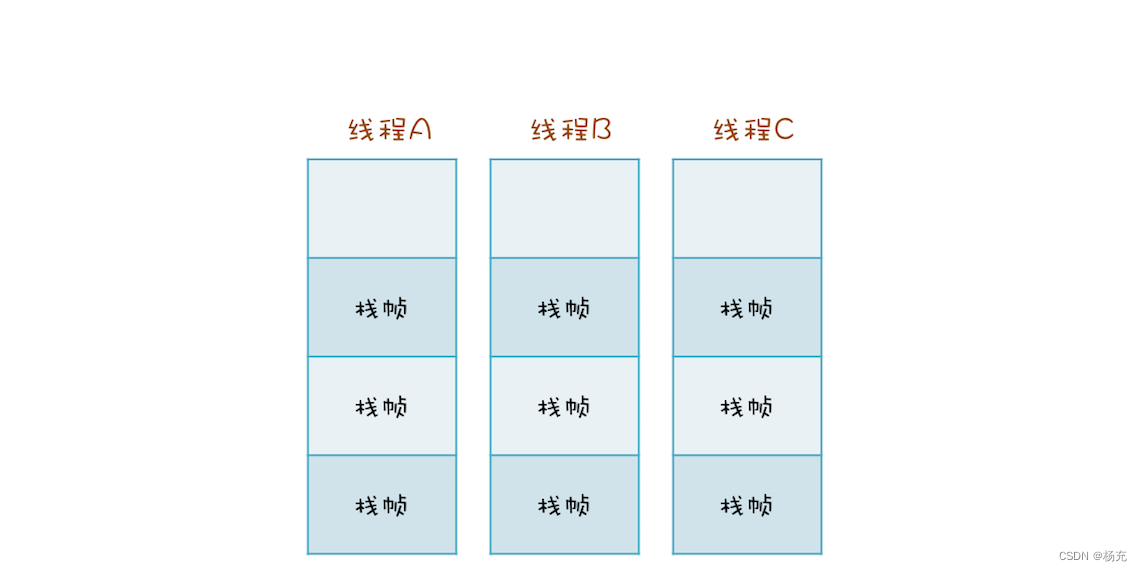
image
- Java 方法里面的局部变量是否存在并发问题?
- 现在你应该很清楚了,一点问题都没有。因为每个线程都有自己的调用栈,局部变量保存在线程各自的调用栈里面,不会共享,所以自然也就没有并发问题。
- 再次重申一遍:没有共享,就没有伤害。
4.2 理解线程本地存储
- 没有共享变量也不会有并发问题,如何避免共享呢?
- 思路其实很简单,对应到并发编程领域,就是每个线程都拥有自己的变量,彼此之间不共享,也就没有并发问题。
- Java 语言提供的线程本地存储(ThreadLocal)就能够做到。
4.3 线程本地存储场景
4.4 ThreadLocal核心设计
4.5 ThreadLocal内存泄漏
- https://www.cnblogs.com/pengxurui/p/17103753.html
4.6 ThreadLocal缺点
4.7 避免共享解决并发总结
- ThreadLocal 超强图解,这次终于懂了~
- https://www.cnblogs.com/pengxurui/p/17103753.html