6.3线程安全如何保证
目录介绍
- 01.线程安全和锁
- 1.1 线程安全概念
- 1.2 锁的分类有哪些
- 1.3 锁的基本概念
- 02.Synchronized锁
- 2.1 JDK每个版本锁
- 2.2 Synchronized实现原理
- 2.3 修饰方法如何实现锁原理
- 2.4 Monitor性能开销
- 2.5 锁升级优化介绍
- 2.6 JVM偏向锁如何实现
- 2.7 JVM轻量级锁实现
- 2.8 JVM自旋锁与重量级锁
- 2.9 动态编译实现锁消除 / 锁粗化
- 2.10 减小锁粒度优化
- 2.11 普通方法VS静态方法
- 03.Lock级别锁
- 3.1 Lock同步锁介绍
- 3.2 Lock和Synchronized区别
- 3.3 Lock和Synchronized性能测试
- 3.4 Lock锁实现原理
- 3.5 锁分离优化Lock锁
- 3.6 读写锁ReentrantReadWriteLock
- 3.7 RRW锁案例实现
- 3.8 读写锁优化StampedLock
- 04.CAS乐观锁
- 4.1 什么是乐观锁
- 4.2 乐观锁实现原理
- 4.3 CAS如何实现原子操作
- 4.4 CAS处理器底层逻辑
- 4.5 优化CAS乐观锁
- 4.6 如何解决ABA问题
- 4.7 有哪些缺点
- 4.8 CAS相比悲观锁效率
- 05.volatile锁
- 5.1 volatile介绍
- 5.2 volatile作用原理
- 5.3 volatile的happens-before
- 5.4 volatile的内存语义
- 5.5 volatile应用场景
- 06.如何写好并发程序
- 6.1 思考如何写好并发
- 6.2 封装共享变量
- 6.3 制定并发访问策略
01.线程安全和锁
1.1 线程安全概念
1.2 锁的分类有哪些
- 大致的分类有这些,这些都是什么意思呢?
- 公平锁/非公平锁
- 乐观锁/悲观锁
- 可重入锁
- 独享锁/共享锁
- 互斥锁/读写锁
- 分段锁
- 偏向锁/轻量级锁/重量级锁
- 可中断锁
- 自旋锁
- Java中一些锁介绍
- Synchronized
- Lock
- CAS
- volatile
1.3 锁的基本概念
02.Synchronized锁
2.1 JDK每个版本锁
- 在 JDK1.5 之前
- Java 是依靠 Synchronized 关键字实现锁功能来做到这点的。Synchronized 是 JVM 实现的一种内置锁,锁的获取和释放是由 JVM 隐式实现。
- JDK1.5 版本
- Synchronized 是基于底层操作系统的 Mutex Lock 实现的,每次获取和释放锁操作都会带来用户态和内核态的切换,从而增加系统性能开销。
- 因此,在锁竞争激烈的情况下,Synchronized 同步锁在性能上就表现得非常糟糕,它也常被大家称为重量级锁。
- 到了 JDK1.6 版本之后
- Java 对 Synchronized 同步锁做了充分的优化,甚至在某些场景下,它的性能已经超越了 Lock 同步锁。
2.2 Synchronized实现原理
- 通常 Synchronized 实现同步锁的方式有两种,一种是修饰方法,一种是修饰方法块。
- 先来看看它的底层实现原理,以下就是通过 Synchronized 实现的两种同步方法加锁的方式:
public class SynchronizedTest { // 关键字在实例方法上,锁为当前实例 public synchronized void method1() { // code } // 关键字在代码块上,锁为括号里面的对象 public void method2() { Object o = new Object(); synchronized (o) { // code } } } - 通过反编译看下具体字节码的实现,运行以下反编译命令
javac SynchronizedTest.java //先运行编译class文件命令 javap -v SynchronizedTest.class //再通过javap打印出字节文件 - 就可以输出我们想要的字节码:
Classfile /Users/yc/github/YCJavaBlog/day6/SynchronizedTest.class Last modified 2018-3-20; size 436 bytes MD5 checksum 01320c0028b5a08fccf74bb389a9ee50 Compiled from "SynchronizedTest.java" public class day6.SynchronizedTest minor version: 0 major version: 52 flags: ACC_PUBLIC, ACC_SUPER Constant pool: #1 = Methodref #2.#16 // java/lang/Object."<init>":()V #2 = Class #17 // java/lang/Object #3 = Class #18 // day6/SynchronizedTest #4 = Utf8 <init> #5 = Utf8 ()V #6 = Utf8 Code #7 = Utf8 LineNumberTable #8 = Utf8 method1 #9 = Utf8 method2 #10 = Utf8 StackMapTable #11 = Class #18 // day6/SynchronizedTest #12 = Class #17 // java/lang/Object #13 = Class #19 // java/lang/Throwable #14 = Utf8 SourceFile #15 = Utf8 SynchronizedTest.java #16 = NameAndType #4:#5 // "<init>":()V #17 = Utf8 java/lang/Object #18 = Utf8 day6/SynchronizedTest #19 = Utf8 java/lang/Throwable { public day6.SynchronizedTest(); descriptor: ()V flags: ACC_PUBLIC Code: stack=1, locals=1, args_size=1 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V 4: return LineNumberTable: line 6: 0 public synchronized void method1(); descriptor: ()V flags: ACC_PUBLIC, ACC_SYNCHRONIZED Code: stack=0, locals=1, args_size=1 0: return LineNumberTable: line 11: 0 public void method2(); descriptor: ()V flags: ACC_PUBLIC Code: stack=2, locals=4, args_size=1 0: new #2 // class java/lang/Object 3: dup 4: invokespecial #1 // Method java/lang/Object."<init>":()V 7: astore_1 8: aload_1 9: dup 10: astore_2 11: monitorenter 12: aload_2 13: monitorexit 14: goto 22 17: astore_3 18: aload_2 19: monitorexit 20: aload_3 21: athrow 22: return Exception table: from to target type 12 14 17 any 17 20 17 any LineNumberTable: line 15: 0 line 16: 8 line 18: 12 line 19: 22 StackMapTable: number_of_entries = 2 frame_type = 255 /* full_frame */ offset_delta = 17 locals = [ class day6/SynchronizedTest, class java/lang/Object, class java/lang/Object ] stack = [ class java/lang/Throwable ] frame_type = 250 /* chop */ offset_delta = 4 } SourceFile: "SynchronizedTest.java" - 通过下面字节码,修改方法method1,锁的底层原理是:
- 当 Synchronized 修饰同步方法时,并没有发现 monitorenter 和 monitorexit 指令,而是出现了一个 ACC_SYNCHRONIZED 标志。
- 这是因为 JVM 使用了 ACC_SYNCHRONIZED 访问标志来区分一个方法是否是同步方法。
- 当方法调用时,调用指令将会检查该方法是否被设置 ACC_SYNCHRONIZED 访问标志。
- 如果设置了该标志,执行线程将先持有 Monitor 对象,然后再执行方法。
- 在该方法运行期间,其它线程将无法获取到该 Mointor 对象,当方法执行完成后,再释放该 Monitor 对象。
- 通过下面字节码,修改代码块method2,锁的底层原理是:
- Synchronized 在修饰同步代码块时,是由 monitorenter 和 monitorexit 指令来实现同步的。
- 进入 monitorenter 指令后,线程将持有 Monitor 对象,退出 monitorenter 指令后,线程将释放该 Monitor 对象。
2.3 修饰方法如何实现锁原理
- 再来看看 Synchronized 修饰方法是怎么实现锁原理的。
- JVM 中的同步是基于进入和退出管程(Monitor)对象实现的。
- 每个对象实例都会有一个 Monitor,Monitor 可以和对象一起创建、销毁。
- Monitor 是由 ObjectMonitor 实现,而 ObjectMonitor 是由 C++ 的 ObjectMonitor.hpp 文件实现,如下所示:
ObjectMonitor() { _header = NULL; _count = 0; //记录个数 _waiters = 0, _recursions = 0; _object = NULL; _owner = NULL; _WaitSet = NULL; //处于wait状态的线程,会被加入到_WaitSet _WaitSetLock = 0 ; _Responsible = NULL ; _succ = NULL ; _cxq = NULL ; FreeNext = NULL ; _EntryList = NULL ; //处于等待锁block状态的线程,会被加入到该列表 _SpinFreq = 0 ; _SpinClock = 0 ; OwnerIsThread = 0 ; } - 核心工作原理,如下所示:
- 当多个线程同时访问一段同步代码时,多个线程会先被存放在 ContentionList 和 _EntryList 集合中,处于 block 状态的线程,都会被加入到该列表。
- 接下来当线程获取到对象的 Monitor 时,Monitor 是依靠底层操作系统的 Mutex Lock 来实现互斥的,线程申请 Mutex 成功,则持有该 Mutex,其它线程将无法获取到该 Mutex,竞争失败的线程会再次进入 ContentionList 被挂起。
- 如果线程调用 wait() 方法,就会释放当前持有的 Mutex,并且该线程会进入 WaitSet 集合中,等待下一次被唤醒。如果当前线程顺利执行完方法,也将释放 Mutex。

image
2.4 Monitor性能开销
- 总结来说就是,同步锁在这种实现方式中,因 Monitor 是依赖于底层的操作系统实现,存在用户态与内核态之间的切换,所以增加了性能开销。
- 线程切换开销:当一个线程进入Monitor并获得锁时,其他线程需要等待。这涉及到线程的切换和调度,会引入一定的开销。
- 竞争和争用开销:当多个线程竞争同一个Monitor的锁时,会引发锁争用。这可能导致线程不断地竞争锁,从而增加了上下文切换和调度的开销。
- 内存屏障开销:在Java中,Monitor的实现通常会使用内存屏障(Memory Barrier)来确保线程间的可见性和有序性。这些内存屏障操作会引入一定的开销。
- 锁粒度开销:如果在代码中过度使用Monitor,将导致锁的粒度过大,从而限制了并发性能。过大的锁粒度可能导致线程之间的竞争增加,降低了并发性能。
2.5 锁升级优化介绍
- JDK1.6 引入了偏向锁、轻量级锁、重量级锁概念,来减少锁竞争带来的上下文切换,而正是新增的 Java 对象头实现了锁升级功能。
- 当 Java 对象被 Synchronized 关键字修饰成为同步锁后,围绕这个锁的一系列升级操作都将和 Java 对象头有关。
- 在 JDK1.6 JVM 中,对象实例在堆内存中被分为了三个部分:对象头、实例数据和对齐填充。
- 其中 Java 对象头由 Mark Word、指向类的指针以及数组长度三部分组成。
- Mark Word 记录了对象和锁有关的信息。Mark Word 在 64 位 JVM 中的长度是 64bit,我们可以一起看下 64 位 JVM 的存储结构是怎么样的。

image
- 锁升级功能主要依赖于 Mark Word 中的锁标志位和释放偏向锁标志位
- Synchronized 同步锁就是从偏向锁开始的,随着竞争越来越激烈,偏向锁升级到轻量级锁,最终升级到重量级锁。
2.6 JVM偏向锁如何实现
- 偏向锁主要用来优化同一线程多次申请同一个锁的竞争。
- 在某些情况下,大部分时间是同一个线程竞争锁资源,例如,在创建一个线程并在线程中执行循环监听的场景下,或单线程操作一个线程安全集合时。
- 同一线程每次都需要获取和释放锁,每次操作都会发生用户态与内核态的切换。
- 偏向锁的作用是什么,有什么作用。
- 当一个线程再次访问这个同步代码或方法时,该线程只需去对象头的 Mark Word 中去判断一下是否有偏向锁指向它的 ID,无需再进入 Monitor 去竞争对象了。
- 当对象被当做同步锁并有一个线程抢到了锁时,锁标志位还是 01,“是否偏向锁”标志位设置为 1,并且记录抢到锁的线程 ID,表示进入偏向锁状态。
- 偏向锁获取和撤销流程
- 一旦出现其它线程竞争锁资源时,偏向锁就会被撤销。偏向锁的撤销需要等待全局安全点,暂停持有该锁的线程,同时检查该线程是否还在执行该方法,如果是,则升级锁,反之则被其它线程抢占。
- 在高并发场景下,当大量线程同时竞争同一个锁资源时,偏向锁就会被撤销,发生 stop the word 后, 开启偏向锁无疑会带来更大的性能开销。

image
- 可以通过添加 JVM 参数关闭偏向锁来调优系统性能,示例代码如下:
-XX:-UseBiasedLocking //关闭偏向锁(默认打开) -XX:+UseHeavyMonitors //设置重量级锁
2.7 JVM轻量级锁实现
- 什么时候从偏向锁升级为轻量级锁
- 当有另外一个线程竞争获取这个锁时,由于该锁已经是偏向锁,当发现对象头 Mark Word 中的线程 ID 不是自己的线程 ID,就会进行 CAS 操作获取锁。
- 如果获取成功,直接替换 Mark Word 中的线程 ID 为自己的 ID,该锁会保持偏向锁状态;如果获取锁失败,代表当前锁有一定的竞争,偏向锁将升级为轻量级锁。
- JVM轻量级锁的场景是什么
- 轻量级锁适用于线程交替执行同步块的场景,绝大部分的锁在整个同步周期内都不存在长时间的竞争。
- 升级轻量级锁及操作流程:

image
2.8 JVM自旋锁与重量级锁
- 轻量级锁 CAS 抢锁失败,线程将会被挂起进入阻塞状态。
- 如果正在持有锁的线程在很短的时间内释放资源,那么进入阻塞状态的线程无疑又要申请锁资源。
- JVM 提供了一种自旋锁
- 可以通过自旋方式不断尝试获取锁,从而避免线程被挂起阻塞。这是基于大多数情况下,线程持有锁的时间都不会太长,毕竟线程被挂起阻塞可能会得不偿失。
- 从 JDK1.7 开始,自旋锁默认启用,自旋次数由 JVM 设置决定,这里不建议设置的重试次数过多,因为 CAS 重试操作意味着长时间地占用 CPU。
- 自旋锁重试之后如果抢锁依然失败,同步锁就会升级至重量级锁,锁标志位改为 10。
- 在这个状态下,未抢到锁的线程都会进入 Monitor,之后会被阻塞在 _WaitSet 队列中。
- 自旋后升级为重量级锁的流程

image
- 在锁竞争不激烈且锁占用时间非常短的场景下,自旋锁可以提高系统性能。
- 一旦锁竞争激烈或锁占用的时间过长,自旋锁将会导致大量的线程一直处于 CAS 重试状态,占用 CPU 资源,反而会增加系统性能开销。
- 所以自旋锁和重量级锁的使用都要结合实际场景。可以通过设置 JVM 参数来关闭自旋锁,优化系统性能,示例代码如下:
-XX:-UseSpinning //参数关闭自旋锁优化(默认打开) -XX:PreBlockSpin //参数修改默认的自旋次数。JDK1.7后,去掉此参数,由jvm控制
2.9 动态编译实现锁消除 / 锁粗化
- 除了锁升级优化,Java 还使用了编译器对锁进行优化。
- JIT 编译器在动态编译同步块的时候,借助了一种被称为逃逸分析的技术,来判断同步块使用的锁对象是否只能够被一个线程访问,而没有被发布到其它线程。
- 确认是的话,那么 JIT 编译器在编译这个同步块的时候不会生成 synchronized 所表示的锁的申请与释放的机器码,即消除了锁的使用。
- 要启用JIT编译器的锁消除优化,可以使用Java虚拟机(JVM)的相关参数进行配置。例如,可以使用-XX:+EliminateLocks参数来启用锁消除优化。
- 在 Java7 之后的版本就不需要手动配置了,该操作可以自动实现。
- 锁粗化同理,就是在 JIT 编译器动态编译时,如果发现几个相邻的同步块使用的是同一个锁实例,那么 JIT 编译器将会把这几个同步块合并为一个大的同步块,从而避免一个线程“反复申请、释放同一个锁”所带来的性能开销。
- 锁消除的一个常见场景
- 在方法内部创建的对象,且该对象不会逃逸到方法外部。在这种情况下,JIT编译器可以推断出该对象不会被其他线程访问,因此可以消除对该对象的同步操作。
2.10 减小锁粒度优化
- 除了锁内部优化和编译器优化之外,我们还可以通过代码层来实现锁优化,减小锁粒度就是一种惯用的方法。
- 当我们的锁对象是一个数组或队列时,集中竞争一个对象的话会非常激烈,锁也会升级为重量级锁。
- 我们可以考虑将一个数组和队列对象拆成多个小对象,来降低锁竞争,提升并行度。
- 最经典的减小锁粒度的案例就是 JDK1.8 之前实现的 ConcurrentHashMap 版本。
- 我们知道,HashTable 是基于一个数组 + 链表实现的,所以在并发读写操作集合时,存在激烈的锁资源竞争,也因此性能会存在瓶颈。
- 而 ConcurrentHashMap 就很很巧妙地使用了分段锁 Segment 来降低锁资源竞争。

image
2.11 普通方法VS静态方法
- 请问以下 Synchronized 同步锁对普通方法和静态方法的修饰有什么区别?
// 修饰普通方法 public synchronized void method1() { // code } // 修饰静态方法 public synchronized static void method2() { // code } - 通过反编译查看代码可知:
- 普通方法的同步锁是对象锁,而静态方法的同步锁是类锁。它们之间的区别在于锁的范围和作用对象。
Classfile /Users/yc/github/YCJavaBlog/SynchronizedTest.class Last modified 2018-6-22; size 304 bytes MD5 checksum 274210267804cdfa3f66474248191de5 Compiled from "SynchronizedTest.java" public class SynchronizedTest minor version: 0 major version: 52 flags: ACC_PUBLIC, ACC_SUPER Constant pool: #1 = Methodref #3.#12 // java/lang/Object."<init>":()V #2 = Class #13 // SynchronizedTest #3 = Class #14 // java/lang/Object #4 = Utf8 <init> #5 = Utf8 ()V #6 = Utf8 Code #7 = Utf8 LineNumberTable #8 = Utf8 method1 #9 = Utf8 method2 #10 = Utf8 SourceFile #11 = Utf8 SynchronizedTest.java #12 = NameAndType #4:#5 // "<init>":()V #13 = Utf8 SynchronizedTest #14 = Utf8 java/lang/Object { public SynchronizedTest(); descriptor: ()V flags: ACC_PUBLIC Code: stack=1, locals=1, args_size=1 0: aload_0 1: invokespecial #1 // Method java/lang/Object."<init>":()V 4: return LineNumberTable: line 4: 0 public synchronized void method1(); descriptor: ()V flags: ACC_PUBLIC, ACC_SYNCHRONIZED Code: stack=0, locals=1, args_size=1 0: return LineNumberTable: line 9: 0 public static synchronized void method2(); descriptor: ()V flags: ACC_PUBLIC, ACC_STATIC, ACC_SYNCHRONIZED Code: stack=0, locals=0, args_size=0 0: return LineNumberTable: line 14: 0 } SourceFile: "SynchronizedTest.java" - 普通方法的同步锁:
- 当synchronized修饰一个普通方法时,它获取的是该方法所属对象的锁,也称为实例锁或对象锁。
- 每个对象实例都有一个关联的锁,当一个线程进入被synchronized修饰的普通方法时,它会获取该对象的锁,其他线程必须等待锁的释放才能进入该方法。
- 不同对象实例的同步方法之间互不影响,每个对象实例都有自己的锁。
- 静态方法的同步锁:
- 当synchronized修饰一个静态方法时,它获取的是该方法所属的类的锁,也称为类锁。
- 类锁是针对整个类的,而不是针对类的实例。无论有多少个对象实例,它们共享同一个类锁。
- 当一个线程进入被synchronized修饰的静态方法时,它会获取该类的锁,其他线程必须等待锁的释放才能进入该方法。
03.Lock级别锁
3.1 Lock同步锁介绍
- Lock 同步锁(以下简称 Lock 锁)需要的是显示获取和释放锁,这就为获取和释放锁提供了更多的灵活性。
- Lock 锁的基本操作是通过乐观锁来实现的,但由于 Lock 锁也会在阻塞时被挂起,因此它依然属于悲观锁。
public void add() { lock.lock(); try { count++; } finally { lock.unlock(); } }
3.2 Lock和Synchronized区别
- 可以通过一张图来简单对比下两个同步锁,了解下各自的特点:
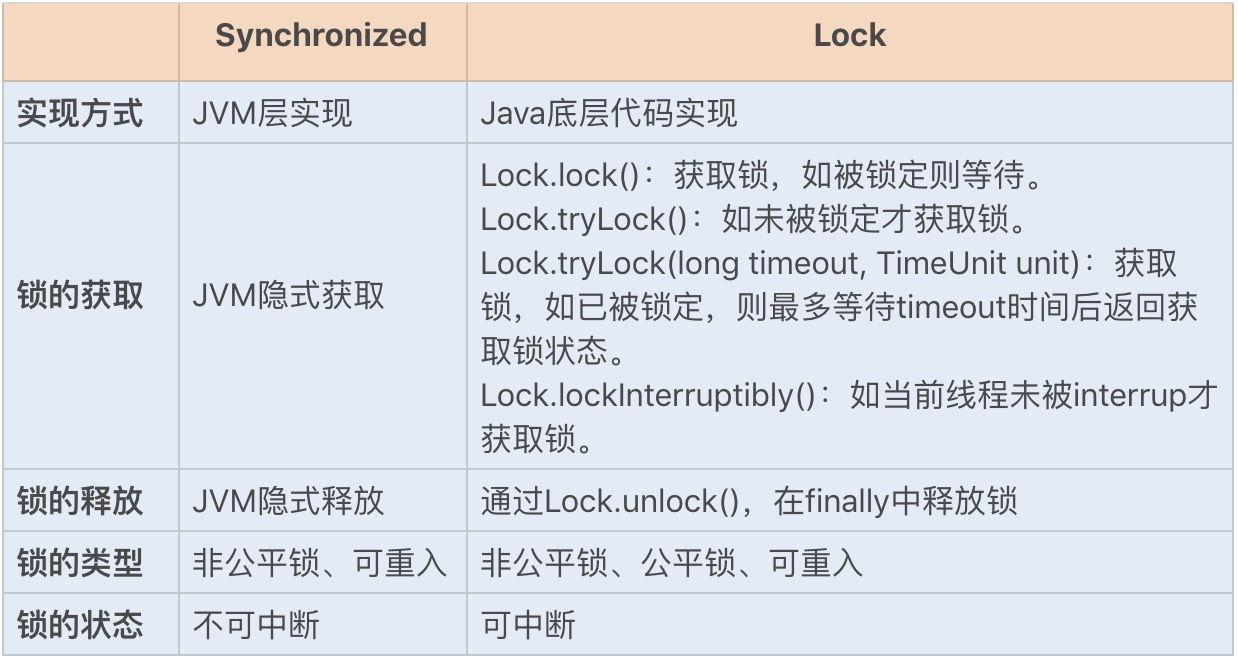
image
- 两者优势对比分析
- 从性能方面上来说,在并发量不高、竞争不激烈的情况下,Synchronized 同步锁由于具有分级锁的优势,性能上与 Lock 锁差不多;
- 但在高负载、高并发的情况下,Synchronized 同步锁由于竞争激烈会升级到重量级锁,性能则没有 Lock 锁稳定。
3.3 Lock和Synchronized性能测试
- 通过一组简单的性能测试,直观地对比下两种锁的性能(吞吐量/线程数),先看一下测试用例,如下所示:
public class SyncTest { private static int count = 0; private static int num = 100; private static int maxValue = 1000; public static void main(String[] args) { Counter lockTest = new SyncTest().new Counter(); long startTime = System.currentTimeMillis(); CountDownLatch latch = new CountDownLatch(num); for (int i = 0; i < num; i++) { new Thread(() -> { for (int cur = 0; cur < maxValue; cur++) { lockTest.add(); } latch.countDown(); }).start(); } try { latch.await(); } catch (InterruptedException e) { e.printStackTrace(); } long endTime = System.currentTimeMillis(); System.out.println("SyncTest执行时长:" + (endTime - startTime) + ", count" + count); } //使用 Synchronized 关键字作为锁 private static String object = "lock"; class Counter { public void add() { synchronized (object) { count++; } } } //使用 lock api级别的锁 private final Lock lock = new ReentrantLock(); class Counter { public void add() { lock.lock(); try { count++; } finally { lock.unlock(); } } } } - 然后分别执行10次,看看两种锁的执行效率分别是多少?
SyncTest执行时长:135, count100000 SyncTest执行时长:178, count100000 SyncTest执行时长:211, count100000 SyncTest执行时长:490, count100000 SyncTest执行时长:316, count100000 SyncTest执行时长:283, count100000 SyncTest执行时长:293, count100000 LockTest执行时长:170, count100000 LockTest执行时长:195, count100000 LockTest执行时长:213, count100000 LockTest执行时长:150, count100000 LockTest执行时长:232, count100000 LockTest执行时长:153, count100000 LockTest执行时长:157, count100000
3.4 Lock锁实现原理
- Lock 锁是基于 Java 实现的锁,Lock 是一个接口类
- 常用的实现类有 ReentrantLock、ReentrantReadWriteLock(RRW),它们都是依赖 AbstractQueuedSynchronizer(AQS)类实现的。
- AQS 类结构中包含一个基于链表实现的等待队列(CLH 队列),用于存储所有阻塞的线程,AQS 中还有一个 state 变量,该变量对 ReentrantLock 来说表示加锁状态。
- 该队列的操作均通过 CAS 操作实现,我们可以通过一张图来看下整个获取锁的流程。

image
3.5 锁分离优化Lock锁
- 虽然 Lock 锁的性能稳定,但也并不是所有的场景下都默认使用 ReentrantLock 独占锁来实现线程同步。
- 对于同一份数据进行读写,如果一个线程在读数据,而另一个线程在写数据,那么读到的数据和最终的数据就会不一致;
- 如果一个线程在写数据,而另一个线程也在写数据,那么线程前后看到的数据也会不一致。
- 这个时候我们可以在读写方法中加入互斥锁,来保证任何时候只能有一个线程进行读或写操作。
- 在大部分业务场景中,读业务操作要远远大于写业务操作。
- 在多线程编程中,读操作并不会修改共享资源的数据,如果多个线程仅仅是读取共享资源,那么这种情况下其实没有必要对资源进行加锁。
- 如果使用互斥锁,反倒会影响业务的并发性能,那么在这种场景下,有没有什么办法可以优化下锁的实现方式呢?
3.6 读写锁ReentrantReadWriteLock
- 针对这种读多写少的场景,Java 提供了另外一个实现 Lock 接口的读写锁 RRW。
- ReentrantLock 是一个独占锁,同一时间只允许一个线程访问。
- RRW 允许多个读线程同时访问,但不允许写线程和读线程、写线程和写线程同时访问。读写锁内部维护了两个锁,一个是用于读操作的 ReadLock,一个是用于写操作的 WriteLock。
- 那读写锁又是如何实现锁分离来保证共享资源的原子性呢?
- RRW 也是基于 AQS 实现的,它的自定义同步器(继承 AQS)需要在同步状态 state 上维护多个读线程和一个写线程的状态,该状态的设计成为实现读写锁的关键。
- RRW 很好地使用了高低位,来实现一个整型控制两种状态的功能,读写锁将变量切分成了两个部分,高 16 位表示读,低 16 位表示写。
- 一个线程尝试获取写锁时,会先判断同步状态 state 是否为 0。
- 如果 state 等于 0,说明暂时没有其它线程获取锁;如果 state 不等于 0,则说明有其它线程获取了锁。
- 此时再判断同步状态 state 的低 16 位(w)是否为 0,如果 w 为 0,则说明其它线程获取了读锁,此时进入 CLH 队列进行阻塞等待;
- 如果 w 不为 0,则说明其它线程获取了写锁,此时要判断获取了写锁的是不是当前线程,若不是就进入 CLH 队列进行阻塞等待;
- 若是,就应该判断当前线程获取写锁是否超过了最大次数,若超过,抛异常,反之更新同步状态。

image
- 一个线程尝试获取读锁时,同样会先判断同步状态 state 是否为 0。
- 如果 state 等于 0,说明暂时没有其它线程获取锁,此时判断是否需要阻塞,如果需要阻塞,则进入 CLH 队列进行阻塞等待;如果不需要阻塞,则 CAS 更新同步状态为读状态。
- 如果 state 不等于 0,会判断同步状态低 16 位,如果存在写锁,则获取读锁失败,进入 CLH 阻塞队列;反之,判断当前线程是否应该被阻塞,如果不应该阻塞则尝试 CAS 同步状态,获取成功更新同步锁为读状态。

image
3.7 RRW锁案例实现
- 下面我们通过一个求平方的例子,来感受下 RRW 的实现,代码如下:
public class TestRTTLock { private double x, y; private ReentrantReadWriteLock lock = new ReentrantReadWriteLock(); // 读锁 private Lock readLock = lock.readLock(); // 写锁 private Lock writeLock = lock.writeLock(); public double read() { //获取读锁 readLock.lock(); try { return Math.sqrt(x * x + y * y); } finally { //释放读锁 readLock.unlock(); } } public void move(double deltaX, double deltaY) { //获取写锁 writeLock.lock(); try { x += deltaX; y += deltaY; } finally { //释放写锁 writeLock.unlock(); } } }
3.8 读写锁优化StampedLock
- RRW 被很好地应用在了读大于写的并发场景中,然而 RRW 在性能上还有可提升的空间。
- 在读取很多、写入很少的情况下,RRW 会使写入线程遭遇饥饿(Starvation)问题,也就是说写入线程会因迟迟无法竞争到锁而一直处于等待状态。
- 在 JDK1.8 中,Java 提供了 StampedLock 类解决了这个问题。
- StampedLock 不是基于 AQS 实现的,但实现的原理和 AQS 是一样的,都是基于队列和锁状态实现的。
- 与 RRW 不一样的是,StampedLock 控制锁有三种模式: 写、悲观读以及乐观读。
- 并且 StampedLock 在获取锁时会返回一个票据 stamp,获取的 stamp 除了在释放锁时需要校验,在乐观读模式下,stamp 还会作为读取共享资源后的二次校验。
- 先通过一个官方的例子来了解下 StampedLock 是如何使用的,代码如下:
public class Point { private double x, y; private final StampedLock s1 = new StampedLock(); void move(double deltaX, double deltaY) { //获取写锁 long stamp = s1.writeLock(); try { x += deltaX; y += deltaY; } finally { //释放写锁 s1.unlockWrite(stamp); } } double distanceFormOrigin() { //乐观读操作 long stamp = s1.tryOptimisticRead(); //拷贝变量 double currentX = x, currentY = y; //判断读期间是否有写操作 if (!s1.validate(stamp)) { //升级为悲观读 stamp = s1.readLock(); try { currentX = x; currentY = y; } finally { s1.unlockRead(stamp); } } return Math.sqrt(currentX * currentX + currentY * currentY); } }
04.CAS乐观锁
4.1 什么是乐观锁
- Synchronized 和 Lock 实现的同步锁机制,这两种同步锁都属于悲观锁,是保护线程安全最直观的方式。
- 悲观锁在高并发的场景下,激烈的锁竞争会造成线程阻塞,大量阻塞线程会导致系统的上下文切换,增加系统的性能开销。
- 那有没有可能实现一种非阻塞型的锁机制来保证线程的安全呢?答案是肯定的。学习下乐观锁的优化方法,看看怎么使用才能发挥它最大的价值。
- 什么是乐观锁
- 乐观锁,顾名思义,就是说在操作共享资源时,它总是抱着乐观的态度进行,它认为自己可以成功地完成操作。
- 但实际上,当多个线程同时操作一个共享资源时,只有一个线程会成功,那么失败的线程呢?它们不会像悲观锁一样在操作系统中挂起,而仅仅是返回,并且系统允许失败的线程重试,也允许自动放弃退出操作。
- 所以,乐观锁相比悲观锁来说,不会带来死锁、饥饿等活性故障问题,线程间的相互影响也远远比悲观锁要小。
- 更为重要的是,乐观锁没有因竞争造成的系统开销,所以在性能上也是更胜一筹。
4.2 乐观锁实现原理
- 来看看乐观锁的实现原理,有助于我们从根本上总结优化方法。
- CAS 是实现乐观锁的核心算法,它包含了 3 个参数:V(需要更新的变量)、E(预期值)和 N(最新值)。
- 只有当需要更新的变量等于预期值时,需要更新的变量才会被设置为最新值,如果更新值和预期值不同,则说明已经有其它线程更新了需要更新的变量,此时当前线程不做操作,返回 V 的真实值。
4.3 CAS如何实现原子操作
- 在 JDK 中的 concurrent 包中,atomic 路径下的类都是基于 CAS 实现的。
- AtomicInteger 就是基于 CAS 实现的一个线程安全的整型类。下面我们通过源码来了解下如何使用 CAS 实现原子操作。
- 我们可以看到 AtomicInteger 的自增方法 getAndIncrement 是用了 Unsafe 的 getAndAddInt 方法,显然 AtomicInteger 依赖于本地方法 Unsafe 类。
- Unsafe 类中的操作方法会调用 CPU 底层指令实现原子操作。
//基于CAS操作更新值 public final boolean compareAndSet(int expect, int update) { return unsafe.compareAndSwapInt(this, valueOffset, expect, update); } //基于CAS操作增1 public final int getAndIncrement() { return unsafe.getAndAddInt(this, valueOffset, 1); }
4.4 CAS处理器底层逻辑
- CAS 是调用处理器底层指令来实现原子操作,那么处理器底层又是如何实现原子操作的呢?
- 处理器和物理内存之间的通信速度要远慢于处理器间的处理速度,所以处理器有自己的内部缓存。
- 如下图所示,在执行操作时,频繁使用的内存数据会缓存在处理器的 L1、L2 和 L3 高速缓存中,以加快频繁读取的速度。

image - 一般情况下,一个单核处理器能自我保证基本的内存操作是原子性的,当一个线程读取一个字节时,所有进程和线程看到的字节都是同一个缓存里的字节,其它线程不能访问这个字节的内存地址。
- 终端/服务器,通常是多处理器,并且每个处理器都是多核的。
- 每个处理器维护了一块字节的内存,每个内核维护了一块字节的缓存,这时候多线程并发就会存在缓存不一致的问题,从而导致数据不一致。
- 这个时候,处理器提供了总线锁定和缓存锁定两个机制来保证复杂内存操作的原子性。
- 当处理器要操作一个共享变量的时候,其在总线上会发出一个 Lock 信号,这时其它处理器就不能操作共享变量了,该处理器会独享此共享内存中的变量。
- 但总线锁定在阻塞其它处理器获取该共享变量的操作请求时,也可能会导致大量阻塞,从而增加系统的性能开销。
- 后来的处理器都提供了缓存锁定机制,也就说当某个处理器对缓存中的共享变量进行了操作,就会通知其它处理器放弃存储该共享资源或者重新读取该共享资源。
4.5 优化CAS乐观锁
- CAS乐观锁也有自己的缺陷
- 虽然乐观锁在并发性能上要比悲观锁优越,但是在写大于读的操作场景下,CAS 失败的可能性会增大,如果不放弃此次 CAS 操作,就需要循环做 CAS 重试,这无疑会长时间地占用 CPU。
- 在 Java7 中,AtomicInteger做了CAS操作:
- AtomicInteger 的 getAndSet 方法中使用了 for 循环不断重试 CAS 操作,如果长时间不成功,就会给 CPU 带来非常大的执行开销。
- 到了 Java8,for 循环虽然被去掉了,但我们反编译 Unsafe 类时就可以发现该循环其实是被封装在了 Unsafe 类中,CPU 的执行开销依然存在。
public final int getAndSet(int newValue) { for (;;) { int current = get(); if (compareAndSet(current, newValue)) return current; } } - 在 JDK1.8 中,Java 提供了一个新的原子类 LongAdder。
- LongAdder 在高并发场景下会比 AtomicInteger 和 AtomicLong 的性能更好,代价就是会消耗更多的内存空间。
- LongAdder 的原理就是降低操作共享变量的并发数
- 也就是将对单一共享变量的操作压力分散到多个变量值上,将竞争的每个写线程的 value 值分散到一个数组中,不同线程会命中到数组的不同槽中,各个线程只对自己槽中的 value 值进行 CAS 操作,最后在读取值的时候会将原子操作的共享变量与各个分散在数组的 value 值相加,返回一个近似准确的数值。
- LongAdder 内部由一个 base 变量和一个 cell[]数组组成。当只有一个写线程,没有竞争的情况下,LongAdder 会直接使用 base 变量作为原子操作变量,通过 CAS 操作修改变量;当有多个写线程竞争的情况下,除了占用 base 变量的一个写线程之外,其它各个线程会将修改的变量写入到自己的槽 cell[]数组中。
4.6 如何解决ABA问题
- ABA问题描述
- 因为CAS会检查旧值有没有变化,这里存在这样一个有意思的问题。比如一个旧值A变为了成B,然后再变成A,刚好在做CAS时检查发现旧值并没有变化依然为A,但是实际上的确发生了变化。
- 解决方案可以沿袭数据库中常用的乐观锁方式,添加一个版本号可以解决。
- 原来的变化路径A->B->A就变成了1A->2B->3A。
- 从Java1.5开始JDK的atomic包里提供了一个类
AtomicStampedReference来解决ABA问题。通过为引用建立类似版本号(stamp)的方式,来保证 CAS 的正确性。 - 这个类的compareAndSet方法作用是首先检查当前引用是否等于预期引用,并且当前标志是否等于预期标志,如果全部相等,则以原子方式将该引用和该标志的值设置为给定的更新值。
4.7 有哪些缺点
- CAS 乐观锁在平常使用时比较受限
- 它只能保证单个变量操作的原子性,当涉及到多个变量时,CAS 就无能为力了,可以用锁来实现。
- CAS 乐观锁在高并发写大于读的场景下,大部分线程的原子操作会失败
- 失败后的线程将会不断重试 CAS 原子操作,这样就会导致大量线程长时间地占用 CPU 资源,给系统带来很大的性能开销。
- 在 JDK1.8 中,Java 新增了一个原子类 LongAdder,它使用了空间换时间的方法,解决了上述问题。
4.8 CAS相比悲观锁效率
05.volatile锁
5.1 volatile介绍
5.2 volatile作用原理
5.3 volatile的happens-before
5.4 volatile的内存语义
5.5 volatile应用场景
06.如何写好并发程序
6.1 思考如何写好并发
- 举例子:开发中的一个场景
- 在设计之初都是直接按照单线程的思路来写程序的,而忽略了本应该重视的并发问题;
- 等上线后的某天,突然发现诡异的 Bug,再历经千辛万苦终于定位到问题所在,却发现对于如何解决已经没有了思路。
- 思考一下,如何写好并发编程
- 可以从封装共享变量、制定并发访问策略这两个方面下手。这块其实用的面向对象思想!
6.2 封装共享变量
- 并发程序,我们关注的一个核心问题,不过是解决多线程同时访问共享变量的问题。
- 面向对象思想里面有一个很重要的特性是封装,封装的通俗解释就是将属性和实现细节封装在对象内部,外界对象只能通过目标对象提供的公共方法来间接访问这些内部属性。
- 把共享变量作为对象的属性,那对于共享变量的访问路径就是对象的公共方法,所有入口都要安排检票程序就相当于我们前面提到的并发访问策略。
- 封装共享变量写好并发编程的核心思路
- 将共享变量作为对象属性封装在内部,对所有公共方法制定并发访问策略。
- 拿很多统计程序都要用到计数器来说,下面的计数器程序共享变量只有一个,就是 value,我们把它作为 Counter 类的属性,并且将两个公共方法 get() 和 addOne() 声明为同步方法,这样 Counter 类就成为一个线程安全的类了。
public class Counter { private long value; synchronized long get(){ return value; } synchronized long addOne(){ return ++value; } } - 对于这些不会发生变化的共享变量,建议你用 final 关键字来修饰。
- 这样既能避免并发问题,也能很明了地表明你的设计意图,表明已经考虑过这些共享变量的并发安全问题了。
6.3 制定并发访问策略
- 制定并发访问策略,是一个非常复杂的事情。应该说整个专栏都是在尝试搞定它。不过从方案上来看,无外乎就是以下“三件事”。
- 1.避免共享:避免共享的技术主要是利于线程本地存储以及为每个任务分配独立的线程。
- 2.不变模式:这个在 Java 领域应用的很少,但在其他领域却有着广泛的应用,例如 Actor 模式、CSP 模式以及函数式编程的基础都是不变模式。
- 3.管程及其他同步工具:Java 领域万能的解决方案是管程,但是对于很多特定场景,使用 Java 并发包提供的读写锁、并发容器等同步工具会更好。
- 除了这些方案之外,还有一些宏观的原则需要你了解。这些宏观原则,有助于你写出“健壮”的并发程序。这些原则主要有以下三条。
- 优先使用成熟的工具类:Java SDK 并发包里提供了丰富的工具类,基本上能满足你日常的需要,建议你熟悉它们,用好它们,而不是自己再“发明轮子”,毕竟并发工具类不是随随便便就能发明成功的。
- 迫不得已时才使用低级的同步原语:低级的同步原语主要指的是 synchronized、Lock、Semaphore 等,这些虽然感觉简单,但实际上并没那么简单,一定要小心使用。
- 避免过早优化:安全第一,并发程序首先要保证安全,出现性能瓶颈后再优化。