6.10并发编程数据一致性
目录介绍
- 00.本节掌握要点
- 01.一个问题思考
- 02.典型回答分析
- 03.考点分析说明
- 04.JMM解决什么
- 05.JMM如何解决问题
- 06.volatile实现JMM
- 07.看案例去分析
00.本节掌握要点
- 1.什么是happen-before关系,这个是什么意思?
01.一个问题思考
- Java 语言在设计之初就引入了线程的概念,以充分利用现代处理器的计算能力,这既带来了强大、灵活的多线程机制,也带来了线程安全等令人混淆的问题,而 Java 内存模型(Java Memory Model,JMM)为我们提供了一个在纷乱之中达成一致的指导准则。
- Java 内存模型中的 happen-before 是什么?
02.典型回答分析
- Happen-before 关系
- 是 Java 内存模型中保证多线程操作可见性的机制,也是对早期语言规范中含糊的可见性概念的一个精确定义。
- 它的具体表现形式,包括但远不止是我们直觉中的 synchronized、volatile、lock 操作顺序等方面,例如:
- 线程内执行的每个操作,都保证 happen-before 后面的操作,这就保证了基本的程序顺序规则,这是开发者在书写程序时的基本约定。
- 对于 volatile 变量,对它的写操作,保证 happen-before 在随后对该变量的读取操作。
- 对于一个锁的解锁操作,保证 happen-before 加锁操作。
- 对象构建完成,保证 happen-before 于 finalizer 的开始动作。
- 甚至是类似线程内部操作的完成,保证 happen-before 其他 Thread.join() 的线程等。
- 这些 happen-before 关系是存在着传递性的,如果满足 a happen-before b 和 b happen-before c,那么 a happen-before c 也成立。
- 用 happen-before,而不是简单说前后,是因为它不仅仅是对执行时间的保证,也包括对内存读、写操作顺序的保证。仅仅是时钟顺序上的先后,并不能保证线程交互的可见性。
03.考点分析说明
- 今天的问题是一个常见的考察 Java 内存模型基本概念的问题,我前面给出的回答尽量选择了和日常开发相关的规则。
- JMM 是面试的热点,可以看作是深入理解 Java 并发编程、编译器和 JVM 内部机制的必要条件,但这同时也是个容易让初学者无所适从的主题。对于学习 JMM,我有一些个人建议:
- 明确目的,克制住技术的诱惑。除非你是编译器或者 JVM 工程师,否则我建议不要一头扎进各种 CPU 体系结构,纠结于不同的缓存、流水线、执行单元等。这些东西虽然很酷,但其复杂性是超乎想象的,很可能会无谓增加学习难度,也未必有实践价值。
- 克制住对“秘籍”的诱惑。有些时候,某些编程方式看起来能起到特定效果,但分不清是实现差异导致的“表现”,还是“规范”要求的行为,就不要依赖于这种“表现”去编程,尽量遵循语言规范进行,这样我们的应用行为才能更加可靠、可预计。
- 这一讲中,兼顾面试和编程实践,我会结合例子梳理下面两点:
- 为什么需要 JMM,它试图解决什么问题?
- JMM 是如何解决可见性等各种问题的?类似 volatile,体现在具体用例中有什么效果?
- Java 内存模型就是特指 JSR-133 中重新定义的 JMM 规范。在特定的上下文里,也许会与 JVM(Java)内存结构等混淆,并不存在绝对的对错,但一定要清楚面试官的本意,有的面试官也会特意考察是否清楚这两种概念的区别。
04.JMM解决什么
- 随着 Java 被运行在越来越多的平台上,人们发现,过于泛泛的内存模型定义,存在很多模棱两可之处,对 synchronized 或 volatile 等,类似指令重排序时的行为,并没有提供清晰规范。这里说的指令重排序,既可以是编译器优化行为,也可能是源自于现代处理器的乱序执行等。
- 换句话说:
- 既不能保证一些多线程程序的正确性,例如最著名的就是双检锁(Double-Checked Locking,DCL)的失效问题,具体可以参考单例模式的说明,双检锁可能导致未完整初始化的对象被访问,理论上这叫并发编程中的安全发布(Safe Publication)失败。
- 也不能保证同一段程序在不同的处理器架构上表现一致,例如有的处理器支持缓存一致性,有的不支持,各自都有自己的内存排序模型。
- Java 迫切需要一个完善的 JMM,能够让普通 Java 开发者和编译器、JVM 工程师,能够清晰地达成共识。换句话说,可以相对简单并准确地判断出,多线程程序什么样的执行序列是符合规范的。
- 对于编译器、JVM 开发者,关注点可能是如何使用类似内存屏障(Memory-Barrier)之类技术,保证执行结果符合 JMM 的推断。
- 对于 Java 应用开发者,则可能更加关注 volatile、synchronized 等语义,如何利用类似 happen-before 的规则,写出可靠的多线程应用,而不是利用一些“秘籍”去糊弄编译器、JVM。
05.JMM如何解决问题
- 介绍了 JVM 内部的运行时数据区,但是真正程序执行,实际是要跑在具体的处理器内核上。你可以简单理解为,把本地变量等数据从内存加载到缓存、寄存器,然后运算结束写回主内存。你可以从下面示意图,看这两种模型的对应。
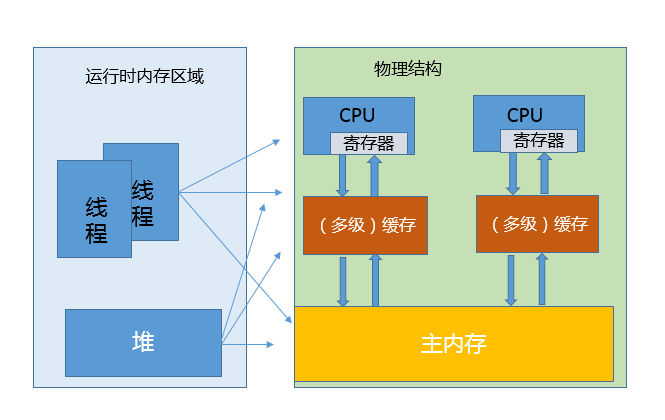
image
- 看上去很美好,但是当多线程共享变量时,情况就复杂了。试想,如果处理器对某个共享变量进行了修改,可能只是体现在该内核的缓存里,这是个本地状态,而运行在其他内核上的线程,可能还是加载的旧状态,这很可能导致一致性的问题。从理论上来说,多线程共享引入了复杂的数据依赖性,不管编译器、处理器怎么做重排序,都必须尊重数据依赖性的要求,否则就打破了正确性!这就是 JMM 所要解决的问题。
- JMM 内部的实现通常是依赖于所谓的内存屏障,通过禁止某些重排序的方式,提供内存可见性保证,也就是实现了各种 happen-before 规则。与此同时,更多复杂度在于,需要尽量确保各种编译器、各种体系结构的处理器,都能够提供一致的行为。
06.volatile实现JMM
- 以 volatile 为例,看看如何利用内存屏障实现 JMM 定义的可见性?对于一个 volatile 变量:
- 对该变量的写操作之后,编译器会插入一个写屏障。
- 对该变量的读操作之前,编译器会插入一个读屏障。
- 内存屏障能够在类似变量读、写操作之后,保证其他线程对 volatile 变量的修改对当前线程可见,或者本地修改对其他线程提供可见性。换句话说,线程写入,写屏障会通过类似强迫刷出处理器缓存的方式,让其他线程能够拿到最新数值。
07.看案例去分析
从应用开发者的角度,JMM 提供的可见性,体现在类似 volatile 上,具体行为是什么样呢?这里循序渐进的举两个例子。
看下面的代码片段,希望达到的效果是,当 condition 被赋值为 false 时,线程 A 能够从循环中退出。
// Thread A while (condition) { } // Thread B condition = false;- 这里就需要 condition 被定义为 volatile 变量,不然其数值变化,往往并不能被线程 A 感知,进而无法退出。当然,也可以在 while 中,添加能够直接或间接起到类似效果的代码。
举 Brian Goetz 提供的一个经典用例,使用 volatile 作为守卫对象,实现某种程度上轻量级的同步,请看代码片段:
Map configOptions; char[] configText; volatile boolean initialized = false; // Thread A configOptions = new HashMap(); configText = readConfigFile(fileName); processConfigOptions(configText, configOptions); initialized = true; // Thread B while (!initialized) sleep(); // use configOptions- JSR-133 重新定义的 JMM 模型,能够保证线程 B 获取的 configOptions 是更新后的数值。
- 也就是说 volatile 变量的可见性发生了增强,能够起到守护其上下文的作用。线程 A 对 volatile 变量的赋值,会强制将该变量自己和当时其他变量的状态都刷出缓存,为线程 B 提供可见性。当然,这也是以一定的性能开销作为代价的,但毕竟带来了更加简单的多线程行为。
使用建议
- 经常会说 volatile 比 synchronized 之类更加轻量,但轻量也仅仅是相对的,volatile 的读、写仍然要比普通的读写要开销更大,所以如果你是在性能高度敏感的场景,除非你确定需要它的语义,不然慎用。
什么是数据的强、弱一致性?
- https://time.geekbang.org/column/article/105756
Java内存模型中的happen-before是什么?
- https://time.geekbang.org/column/article/10772