1.1String深入理解原理
目录介绍
- 01.String基础概念
- 1.1 String问题答疑
- 1.2 String创建机理
- 1.3 String类考点分析
- 02.String核心设计思想
- 2.1 字符串设计和实现考量
- 2.2 典型的Immutable类
- 2.3 字符串常量池
- 2.4 字符串缓存设计
- 2.5 字符串intern设计
- 2.6 char数组换成byte数据设计
- 2.7 JDK每个版本优化点
- 03.String使用思考
- 3.1 String不可变的好处
- 3.2 String存放字符串限制
- 3.3 String对+重载做了什么
- 3.4 switch对字符串支持吗
- 3.5 优雅使用字符串分割
- 04.StringBuffer
- 4.1 为何要有StringBuffer
- 4.2 StringBuffer设计要点
- 4.3 Buffer和Builder区别
01.String基础概念
1.1 String问题答疑
- 基础的问题思考,如下所示:
- String字符串是如何设计与实现考量的?String为什么要设计成不可变的?有何优缺点?
- String字符串缓存 intern()方法,由永久代移到堆中。请说下String与StringBuffer区别?
- String 的演化,Java 9 中底层把 char 数组换成了 byte 数组,占用更少的空间,为什么要这样设计?
1.2 String创建机理
- 由于String在Java世界中使用过于频繁,Java为了避免在一个系统中产生大量的String对象,引入了字符串常量池。
- 其运行机制是:创建一个字符串时,首先检查池中是否有值相同的字符串对象,如果有则不需要创建直接从池中刚查找到的对象引用;如果没有则新建字符串对象,返回对象引用,并且将新创建的对象放入池中。
- 但是,通过new方法创建的String对象是不检查字符串池的,而是直接在堆区或栈区创建一个新的对象,也不会把对象放入池中。
- 上述原则只适用于通过直接量给String对象引用赋值的情况。举例:
- 通过三种不同的方式创建了三个对象,再依次两两匹配,每组被匹配的两个对象是否相等?思考为什么?
String str1 = "123"; //通过直接量赋值方式,放入字符串常量池 String str2 = new String(“123”);//通过new方式赋值方式,不放入字符串常量池。直接在堆内存空间创建一个新的对象 String str3= str2.intern(); System.out.println(str1==str2);//false System.out.println(str2==str3);//false System.out.println(str1==str3);//true - 注意:String提供了intern()方法。
- 调用该方法时,如果常量池中包括了一个等于此String对象的字符串(由equals方法确定),则返回池中的字符串。否则,将此String对象添加到池中,并且返回此池中对象的引用。
1.3 String类考点分析
- 一些考点分析,由考点来了解前因后果的字符串设计思想
- 通过 String 和相关类,考察基本的线程安全设计与实现,各种基础编程实践。
- 考察 JVM 对象缓存机制的理解以及如何良好地使用。
- 考察 JVM 优化 Java 代码的一些技巧。
- String 相关类的演进,比如 Java 9 中实现的巨大...
02.String核心设计思想
2.1 字符串设计和实现考量
- String 是 Immutable 类的典型实现
- 原生的保证了基础线程安全,因为你无法对它内部数据进行任何修改,这种便利甚至体现在拷贝构造函数中,由于不可变,Immutable 对象在拷贝时不需要额外复制数据。
- 将String设计为不可变的带来了安全性、线程安全性、效率和可靠性等方面的优势。这使得字符串操作更加简单、可靠,并且提供了一些优化机制来提高性能。
- String 为何设计成不可变
- 安全性:不可变的字符串是线程安全的,因为多个线程可以同时访问和共享相同的字符串对象,而无需担心数据的修改。这简化了多线程编程的复杂性,无需额外的同步措施。
- 效率:由于字符串是不可变的,可以进行一些优化。例如,字符串的哈希值(hash code)可以在创建时计算并缓存,避免重复计算。比如作为Map的key。
- 字符串常量池:Java中的字符串常量池是一个特殊的内存区域,用于存储字符串常量。由于字符串是不可变的,可以在字符串常量池中共享相同的字符串对象,以节省内存空间。
- 安全性和可靠性:不可变的字符串可以确保字符串的值不会被意外修改。这对于一些安全性要求较高的场景非常重要,例如密码、加密等。
- 缓存和重用:由于字符串是不可变的,可以安全地将字符串缓存起来以供重复使用。这在一些性能敏感的场景中非常有用,避免了频繁的字符串创建和销毁。
2.2 典型的Immutable类
- String类是典型的Immutable类
- 是典型的 Immutable 类,被声明成为 final class,所有属性也都是 final 的。也由于它的不可变,类似拼接、裁剪字符串等动作,都会产生新的 String 对象。
- String主要的三个成员变量
- char value[], int offset, int count均是private,final的,并且没有对应的 getter/setter;
- String 对象一旦初始化完成,上述三个成员变量就不可修改;并且其所提供的接口任何对这些域的修改都将返回一个新对象;
- 是典型的 Immutable 类,被声明成为 final class,所有属性也都是final的。
- 也由于它的不可变,类似拼接、裁剪字符串等动作,都会产生新的 String 对象。
2.3 字符串常量池
- String 类型的常量池比较特殊。它的主要使用方法有两种:
- 直接使用双引号声明出来的 String 对象会直接存储在常量池中。
- 如果不是用双引号声明的 String 对象,可以使用 String 提供的 intern 方String.intern() 是一个 Native 方法。
- 下面举一个例子分析:
- 如果运行时常量池中已经包含一个等于此 String 对象内容的字符串,则返回常量池中该字符串的引用;
- 如果没有,则在常量池中创建与此 String 内容相同的字符串,并返回常量池中创建的字符串的引用。
String s1 = new String("yc"); String s2 = s1.intern(); String s3 = "yc"; System.out.println(s2);//yc System.out.println(s1 == s2);//false,因为一个是堆内存中的String对象一个是常量池中的String对象, System.out.println(s3 == s2);//true,因为两个都是常量池中的String对
2.4 字符串缓存设计
- String 在 Java 6 以后提供了 intern()方法,目的是提示 JVM 把相应字符串缓存起来,以备重复使用。
- 在我们创建字符串对象并调用 intern() 方法的时候,如果已经有缓存的字符串,就会返回缓存里的实例,否则将其缓存起来。
- 在后续版本中,这个缓存被放置在堆中
- 为何这样做?这样就极大避免了永久代占满的问题,甚至永久代在 JDK 8 中被 MetaSpace(元数据区)替代了。而且,默认缓存大小也在不断地扩大中,从最初的 1009,到 7u40 以后被修改为 60013。
2.5 字符串intern设计
- 经典反例
- 平常编程时,对一个String对象str赋值“hello”,然后又让str值为“world”,这个时候str的值变成了“world”。那么str值确实改变了,为什么还说String对象不可变呢?
- 首先解释什么是对象和对象引用。在Java中要比较两个对象是否相等,往往是用 == ,而要判断两个对象的值是否相等,则需要用equals方法来判断。
- 这是因为str只是String对象的引用,并不是对象本身。对象在内存中是一块内存地址,str则是一个指向该内存地址的引用。所以刚刚这个例子中,第一次赋值的时候,创建了一个“hello”对象,str引用指向“hello”地址;第二次赋值的时候,又重新创建了一个对象“world”,str引用指向了“world”,但“hello”对象依然存在于内存中。
- 也就是说 str 并不是对象,而只是一个对象的引用。真正的对象依然还在内存中,没有被改变。
- 如何使用String.intern节省内存?
String a = new String("abc").intern(); String b = new String("abc").intern(); if(a == b){ System.out.print("a == b"); } //输出结果 //a == b- 在字符串常量中,默认会将对象放入常量池;在字符串变量中,对象是会创建在堆内存中,同时也会在常量池中创建一个字符串对象,复制到堆内存对象中,并返回堆内存对象引用。
- 如果调用 intern 方法,会去查看字符串常量池中是否有等于该对象的字符串的引用,如果没有,在JDK1.6版本中会复制堆中的字符串到常量池中,并返回该字符串引用,堆内存中原有的字符串由于没有引用指向它,将会通过垃圾回收器回收。
- 在JDK1.7版本之后,由于常量池已经合并到了堆中,所以不会再复制具体字符串了,只是会把首次遇到的字符串的引用添加到常量池中;如果有,就返回常量池中的字符串引用。
2.6 char数组换成byte数据设计
- Java 9引入了Compact Strings特性,这是一种优化字符串内部表示的方式。
- 在Java 8及之前的版本中,String类使用char数组来存储字符序列,每个char占用2个字节。这对于大部分的ASCII字符来说是一种浪费,因为它们只需要占用1个字节。
- 为何要将char数组换成byte数据
- 为了节省内存空间,Java 9中的Compact Strings特性将String类的内部表示从char数组改为byte数组。这意味着对于只包含ASCII字符的字符串,每个字符只需要占用1个字节的空间,而不再是2个字节。
- 将char数组换成byte数据,对只包含ASCII字符的字符串进行内存优化,减少了字符串对象的内存占用。这种设计可以在存储大量ASCII字符的字符串时节省内存空间。
2.7 JDK每个版本优化点
- 在Java语言中,Sun公司的工程师们对String对象做了大量的优化,来节约内存空间,提升String对象在系统中的性能。
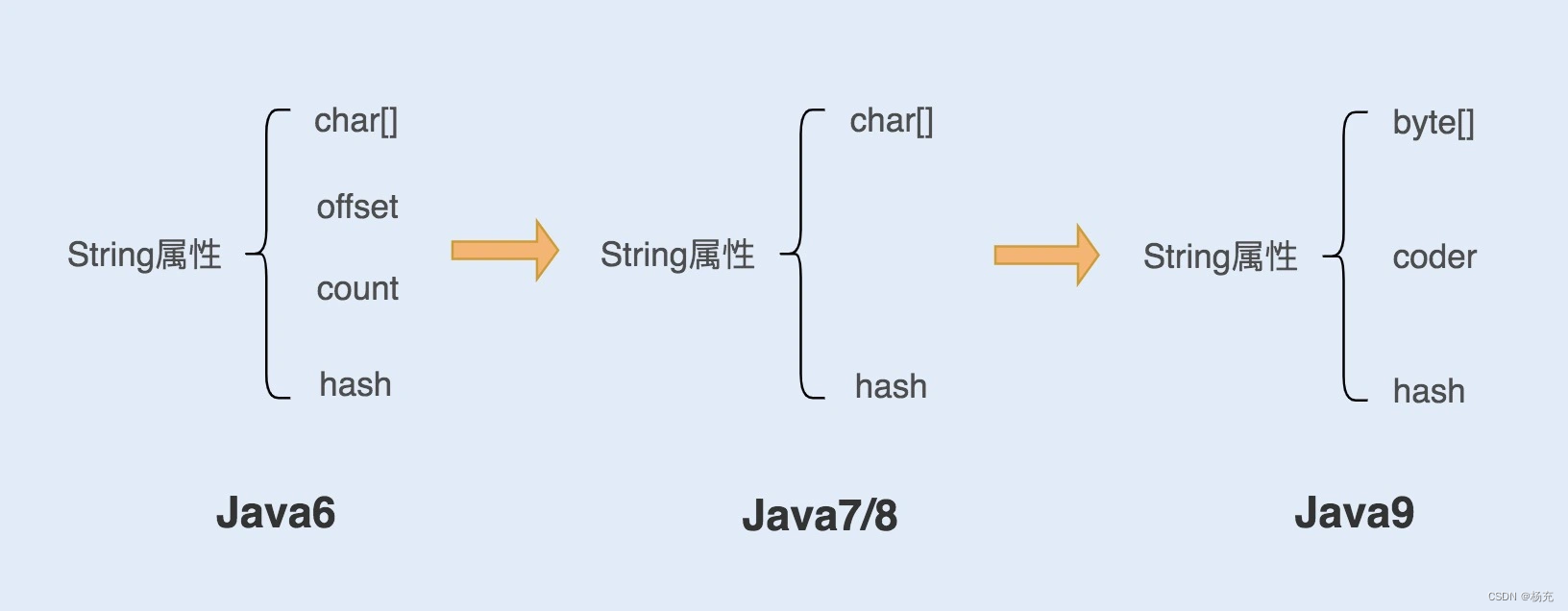
image
- 在Java6以及之前的版本中
- String对象是对char数组进行了封装实现的对象,主要有四个成员变量:char数组、偏移量offset、字符数量count、哈希值hash。
- String对象是通过offset和count两个属性来定位char[]数组,获取字符串。这么做可以高效、极速地共享数组对象,同时节省内存空间,但这种方式很有可能会导致内存泄露。
- 为什么会导致内存泄露?在Java6中substring方法会调用new string构造函数,此时会复用原来的char数组,而如果我们仅仅是用substring获取一小段字符,而原本string字符串非常大的情况下,substring的对象如果一直被引用,由于substring的里面的char数组仍然指向原字符串,此时string字符串也无法回收,从而导致内存泄露。
- 试想下,如果有大量这种通过substring获取超大字符串中一小段字符串的操作,会因为内存泄露而导致内存溢出。
- 从Java7版本开始到Java8版本
- Java对String类做了一些改变。String类中不再有offset和count两个变量了。这样的好处是String对象占用的内存稍微少了些,同时String.substring方法也不再共享char[],从而解决了使用该方法可能导致的内存泄露问题。
- 从Java9版本开始
- 工程师将char[]字段改为了byte[]字段,又维护了一个新的属性codeer,它是一个编码格式的标识。
- 为何这样修改?一个char字符占16位,2个字节。这个情况下,存储单字节编码内的字符(占一个字节的字符)就显得非常浪费。JDK1.9的String类为了节约内存空间,于是使用了占8位,1个字节的byte数组来存放字符串。
- 新属性coder的作用是,在计算字符串长度或者使用indexOf()函数时,需要根据这个字段,判断如何计算字符串长度。coder属性默认有0和1两个值,0代表Latin-1(单字节编码),1代表UTF-16。如果String判断字符串只包含了Latin-1,则coder属性值为0,反之则为1。
03.String使用思考
3.1 String不可变的好处
- 可以缓存 hash 值
- 因为 String 的 hash 值经常被使用,例如 String 用做 HashMap 的 key。不可变的特性可以使得 hash 值也不可变,因此只需要进行一次计算。
- String Pool 的需要
- 如果一个String对象已经被创建过了,那么就会从 String Pool 中取得引用。只有 String 是不可变的,才可能使用 String Pool。
- 安全性
- String 经常作为参数,String 不可变性可以保证参数不可变。例如在作为网络连接参数的情况下如果 String 是可变的,那么在网络连接过程中,String 被改变,改变 String 对象的那一方以为现在连接的是其它主机,而实际情况却不一定是。
- 线程安全
- String 不可变性天生具备线程安全,可以在多个线程中安全地使用。
3.2 String存放字符串限制
- 我们一般并不会用到过长的字符串,但是实际上String可存储字符串的长度是有约束的,问题来了:最长是多少?为什么?
- 看到问题的第一闪念就是打开源码,找一找有无长度限制代码。很抱歉,那是没有的。然后区分一下字符串的类型,字面量与变量,jvm 对这两者有着截然不同的处理方式。
3.2.1 字面量
- 字面量我的理解就是在程序编译之前就一定指定了值的变量,当然只能限定于基本类型以及字符串,代码中一般是这样的:String s = "字面量";int a = 100;
- JVM 的对字面量的处理
- jvm 会将这些字面量存储在运行时数据区的方法区的常量池中,那么字面量类型的字符串的长度限制就是字符串常量池大小的限制了。
- 常量池大小
- 字符串常量池使用 CONSTANT_UTF8_INFO 类型存储字符串字面量,大小限制是无符号的 16 位整数,因此理论上允许最大长度为 65536 字节。
- ps:utf-8 一个中文占三个字节,就是理论最多能存 21845.333 个中文。
3.2.2 变量
- 也就是 new 出来的对象,比如从 IO 读取来的,注意:编译期之前 new String() 会被处理成字面量。
- 变量类的长度限制就是 String 内部用于存储的数组的长度限制了,也就是 Int 的最大值。
3.3 String对+重载做了什么
3.3.1 使用+拼接字符串
- 在Java中,拼接字符串最简单的方式就是直接使用符号
+来拼接。如:String wechat = "Hollis"; String introduce = "每日更新Java相关技术文章"; String hollis = wechat + "," + introduce; - 这里要特别说明一点,有人把Java中使用
+拼接字符串的功能理解为运算符重载。- 其实并不是,Java是不支持运算符重载的。这其实只是Java提供的一个语法糖。后面再详细介绍。
- 运算符重载:
- 在计算机程序设计中,运算符重载(英语:operator overloading)是多态的一种。运算符重载,就是对已有的运算符重新进行定义,赋予其另一种功能,以适应不同的数据类型。
- 语法糖:
- 语法糖(Syntactic sugar),也译为糖衣语法,是由英国计算机科学家彼得·兰丁发明的一个术语,指计算机语言中添加的某种语法,这种语法对语言的功能没有影响,但是更方便程序员使用。语法糖让程序更加简洁,有更高的可读性。
3.3.2 +拼接字符串原理
- 来一道思考题:很明确,代码输出的结果是:"111111222222",但是它工作原理是怎样的呢?
String str1 = "111111"; String str2 = "222222"; String str = str1 + str2; System.out.println(str); - 由于字符串拼接太常用了,java才支持可以直接用+号对两个字符串进行拼接。
- 其真正实现的原理是中间通过建立临时的StringBuilder对象,然后调用append方法实现。
- 如何验证呢?
- 上述代码文件写在Test.java main方法中,使用javac Test.java编译,在执行javap -verbose Test,可以看到如下信息:
0: ldc #2 // String 111111 2: astore_1 3: ldc #3 // String 222222 5: astore_2 6: new #4 // class java/lang/StringBuilder 9: dup 10: invokespecial #5 // Method java/lang/StringBuilder."":()V 13: aload_1 14: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; 17: aload_2 18: invokevirtual #6 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; 21: invokevirtual #7 // Method java/lang/StringBuilder.toString:()Ljava/lang/String; 24: astore_3 25: getstatic #8 // Field java/lang/System.out:Ljava/io/PrintStream; 28: aload_3 29: invokevirtual #9 // Method java/io/PrintStream.println:(Ljava/lang/String;)V 32: return - 对于java来说,这段代码原理上应该是:
String str1 = "111111"; String str2 = "222222"; StringBuilder sb = new StringBuilder(); sb.append(str1); sb.append(str2); String str = sb.toString(); System.out.println(str); - 再来一道思考题,如下代码的执行结果是什么?是报错,还是"null222222"
- 正确答案是:"null222222"。
String str1 = null; String str2 = "222222"; String str = str1 + str2; System.out.println(str); - 代码原理如下所示
- 这段代码,StringBuilder对象append一个null字符串会怎么处理呢,这就要去查看源码了。
- 然后看super.append(sb),该方法继承了父类的方法,父类为AbstractStringBuilder,再去父类中查看append方法
- String字符串拼接通过StringBuilder走中间过程,通过append方法实现。null拼接会变成字符串"null"
- 程序有大量字符串拼接时,建议考虑直接写StringBuilder实现,就不需要底层new很多临时sb对象了。
3.4 switch对字符串支持吗
- 有一点Java开发经验的人这个时候都会猜测switch对String的支持是使用equals()方法和hashcode()方法。
- 记住,switch中只能使用整型,比如
byte。short,char(ackii码是整型)以及int。还好hashCode()方法返回的是int,而不是long。通过这个很容易记住hashCode返回的是int这个事实。 - 仔细看下可以发现,进行
switch的实际是哈希值,然后通过使用equals方法比较进行安全检查,这个检查是必要的,因为哈希可能会发生碰撞。 - 因此它的性能是不如使用枚举进行switch或者使用纯整数常量,但这也不是很差。因为Java编译器只增加了一个
equals方法,如果你比较的是字符串字面量的话会非常快,比如”abc” ==”abc”。如果你把hashCode()方法的调用也考虑进来了,那么还会再多一次的调用开销,因为字符串一旦创建了,它就会把哈希值缓存起来。 - 因此如果这个
switch语句是用在一个循环里的,比如逐项处理某个值,或者游戏引擎循环地渲染屏幕,这里hashCode()方法的调用开销其实不会很大。
- 记住,switch中只能使用整型,比如
3.5 优雅使用字符串分割
- 字符串的分割,这种方法在编码中也很最常见。
- Split() 方法使用了正则表达式实现了其强大的分割功能,而正则表达式的性能是非常不稳定的,使用不恰当会引起回溯问题,很可能导致 CPU 居高不下。
- 应该慎重使用 Split() 方法,可以用 String.indexOf() 方法代替 Split() 方法完成字符串的分割。如果实在无法满足需求,你就在使用 Split() 方法时,对回溯问题加以重视就可以了。
- 那么在继续深问一下,为何Split方法有风险?
- split()方法基于指定的正则表达式作为分隔符,将字符串分割成多个部分,并返回一个字符串数组。
04.StringBuffer
4.1 为何要有StringBuffer
- 为什么要设计StringBuffer这个类
- StringBuffer是一个可变的字符串类,用于处理可变的字符串操作。它的存在是为了解决String类的不可变性带来的一些限制。
- 那么什么时候会用到StringBuffer这个类
- 对于频繁的字符串操作,使用不可变的String对象可能会导致性能问题,因为每次操作都需要创建新的对象。这时,StringBuffer就派上了用场。
- StringBuffer类提供了一系列可变的字符串操作方法,例如拼接、插入、删除、替换等。它允许在原始的字符串缓冲区上进行修改,而不是创建新的对象。这样可以避免频繁的对象创建和销毁,提高了性能和效率。
4.2 StringBuffer设计要点
- StringBuffer的设计要点有哪些呢
- 可变性:与不可变的String类不同,StringBuffer允许在原始字符串上进行原地修改,而不需要创建新的字符串对象。
- 线程安全性:StringBuffer是线程安全的,适用于多线程环境。它的方法使用synchronized关键字进行同步,确保在多个线程同时访问时的数据一致性。
- 可变长度:StringBuffer可以根据需要动态调整内部字符数组的长度。它会自动扩展内部缓冲区的大小,以容纳更多的字符。这样可以避免频繁的数组复制操作,提高性能。
- 字符串操作方法:这些方法使得对字符串的修改和操作变得简单和方便,如append()用于追加字符串,insert()用于插入字符串,delete()用于删除字符,replace()用于替换字符等。
4.3 Buffer和Builder区别
StringBuffer/StringBuilder有什么区别
- StringBuffer还是线程安全的,它的方法都是同步的(即使用synchronized关键字进行了同步)。这使得StringBuffer适用于多线程环境下的字符串操作,保证了线程安全性。
- Java 5及以后的版本引入了StringBuilder类,它与StringBuffer类类似,但不是线程安全的。如果在单线程环境下进行字符串操作,推荐使用StringBuilder,因为它的性能更好。
StringBuffer和StringBuilder都实现了AbstractStringBuilder抽象类,拥有几乎一致对外提供的调用接口。
- 其底层在内存中的存储方式与String相同,都是以一个有序的字符序列(char类型的数组)进行存储,不同点是StringBuffer/StringBuilder对象的值是可以改变的,并且值改变以后,对象引用不会发生改变。
- 两者对象在构造过程中,首先按照默认大小申请一个字符数组,由于会不断加入新数据,当超过默认大小后,会创建一个更大的数组,并将原先的数组内容复制过来,再丢弃旧的数组。
- 因此,对于较大对象的扩容会涉及大量的内存复制操作,如果能够预先评估大小,可提升性能。
如何实现修改字符序列的目的
- StringBuffer 和 StringBuilder 底层都是利用可修改的(char,JDK 9 以后是 byte)数组,二者都继承了 AbstractStringBuilder,里面包含了基本操作,区别仅在于最终的方法是否加了 synchronized。
- 这个内部数组应该创建成多大的呢?如果太小,拼接的时候可能要重新创建足够大的数组;如果太大,又会浪费空间。目前的实现是,构建时初始字符串长度加 16(这意味着,如果没有构建对象时输入最初的字符串,那么初始值就是 16)。
- 如果确定拼接会发生非常多次,而且大概是可预计的,那么就可以指定合适的大小,避免很多次扩容的开销。扩容会产生多重开销,因为要抛弃原有数组,创建新的(可以简单认为是倍数)数组,还要进行arraycopy。
String、StringBuffer、StringBuilder有什么区别?
- https://time.geekbang.org/column/article/7349