5.6线程池设计核心原理
目录介绍
- 01.线程池设计思想
- 1.1 池化设计的思想
- 1.2 一般池的使用场景
- 1.3 线程池设计思想
- 02.设计线程池实践
- 2.1 如何设计线程池
- 2.2 线程池设计核心点
- 2.3 如何设计线程复用
- 2.4 如何设计线程管理
- 2.5 如何设计任务队列
- 2.6 如何设计任务分离
- 2.7 如何设计线程调度
- 2.8 如何设计线程安全
- 2.9 如何设计监控
01.线程池设计思想
1.1 池化设计的思想
- 线程池思维的启蒙
- 在初次接触并发包里线程池相关的工具类时,多少会都有点蒙,不知道该从哪里入手,根本原因在于线程池和一般意义上的池化资源是不同的。
- 一般意义上的池化资源,当你需要资源的时候就调用 acquire() 方法来申请资源,用完之后就调用 release() 释放资源。
- 若你带着这个固有模型来看并发包里线程池相关的工具类时,会很遗憾地发现它们完全匹配不上,Java 提供的线程池里面压根就没有申请线程和释放线程的方法。
1.2 一般池的使用场景
- Glide大量使用对象池Pools来对频繁需要创建和销毁的代码进行优化。
- 比如Glide中,每个图片请求任务,都需要用到 EngineJob 、DecodeJob类。若每次都需要重新new这些类,并不是很合适。而且在大量图片请求时,频繁创建和销毁这些类,可能会导致内存抖动,影响性能。
- Glide使用对象池的机制,对这种频繁需要创建和销毁的对象保存在一个对象池中。每次用到该对象时,就取对象池空闲的对象,并对它进行初始化操作,从而提高框架的性能。
- 这种对象池的设计核心代码如下所示
//采用一般意义上池化资源的设计方法 public class SimplePool<T> implements Pool<T> { // 获取空闲线程 T acquire() { } // 释放线程 void release(T t){ } } class Test{ public void test() { //期望的使用 SimplePool<Thread> pool = new SimplePool<>(); //使用 Thread t1 = pool.acquire(); //传入Runnable对象 t1.execute(()->{ //具体业务逻辑 }); //释放 pool.release(t1); } }
1.3 线程池设计思想
- 为什么线程池没有采用一般意义上池化资源的设计方法呢?
- 如果线程池采用一般意义上池化资源的设计方法,你可以来思考一下,假设我们获取到一个空闲线程 T1,然后该如何使用 T1 呢?
- 你期望的可能是这样:通过调用 T1 的 execute() 方法,传入一个 Runnable 对象来执行具体业务逻辑,就像通过构造函数 Thread(Runnable target) 创建线程一样。
- 可惜的是,你翻遍 Thread 对象的所有方法,都不存在类似 execute(Runnable target) 这样的公共方法。
- 那线程池该如何设计呢?
- 目前业界线程池的设计,普遍采用的都是生产者 - 消费者模式。线程池的使用方是生产者,线程池本身是消费者。
02.设计线程池实践
2.1 如何设计线程池
- 采用:生产者 - 消费者模式。
- 线程池的使用方是生产者,线程池本身是消费者。用队列来存储任务,用集合来存储工作线程。
- 创建了一个非常简单的线程池 MyThreadPool,你可以通过它来理解线程池的工作原理。
- 维护了一个阻塞队列 workQueue 和一组工作线程,工作线程的个数由构造函数中的 poolSize 来指定。
- 用户通过调用 execute() 方法来提交 Runnable 任务,execute() 方法的内部实现仅仅是将任务加入到 workQueue 中。
- ThreadPool 内部维护的工作线程会消费 workQueue 中的任务并执行任务,相关的代码就是代码①处的 while 循环。
//简化的线程池,仅用来说明工作原理 class MyThreadPool{ //利用阻塞队列实现生产者-消费者模式 BlockingQueue<Runnable> workQueue; //保存内部工作线程 List<WorkerThread> threads = new ArrayList<>(); // 构造方法 MyThreadPool(int poolSize, BlockingQueue<Runnable> workQueue){ this.workQueue = workQueue; // 创建工作线程 for(int idx=0; idx<poolSize; idx++){ WorkerThread work = new WorkerThread(); work.start(); threads.add(work); } } // 提交任务 void execute(Runnable command){ workQueue.put(command); } // 工作线程负责消费任务,并执行任务 class WorkerThread extends Thread{ public void run() { //循环取任务并执行 while(true){ //① Runnable task = workQueue.take(); task.run(); } } } } /** 下面是使用示例 **/ class Test{ public void test() { // 创建有界阻塞队列 BlockingQueue<Runnable> workQueue = new LinkedBlockingQueue<>(2); // 创建线程池 MyThreadPool pool = new MyThreadPool(10, workQueue); // 提交任务 pool.execute(()->{ System.out.println("hello"); }); } }
2.2 线程池设计核心点
- 思考1: 用什么来实现池子?
2.3 如何设计线程复用
2.4 如何设计线程管理
2.5 如何设计任务队列
2.6 如何设计任务分离
2.7 如何设计线程调度
2.8 如何设计线程安全
2.9 如何设计监控
2.3 会遇到那些问题
03.考点分析说明
- 在大多数应用场景下
- 使用 Executors 提供的 5 个静态工厂方法就足够
- 但是仍然可能需要直接利用 ThreadPoolExecutor 等构造函数创建,这就要求你对线程构造方式有进一步的了解,你需要明白线程池的设计和结构。
- ExecutorService 除了通常意义上“池”的功能,还提供了更全面的线程管理、任务提交等方法。Executor 框架可不仅仅是线程池,至少下面几点值得深入学习:
- 掌握 Executor 框架的主要内容,至少要了解组成与职责,掌握基本开发用例中的使用。
- 对线程池和相关并发工具类型的理解,甚至是源码层面的掌握。
- 实践中有哪些常见问题,基本的诊断思路是怎样的。
- 如何根据自身应用特点合理使用线程池。
04.知识拓展
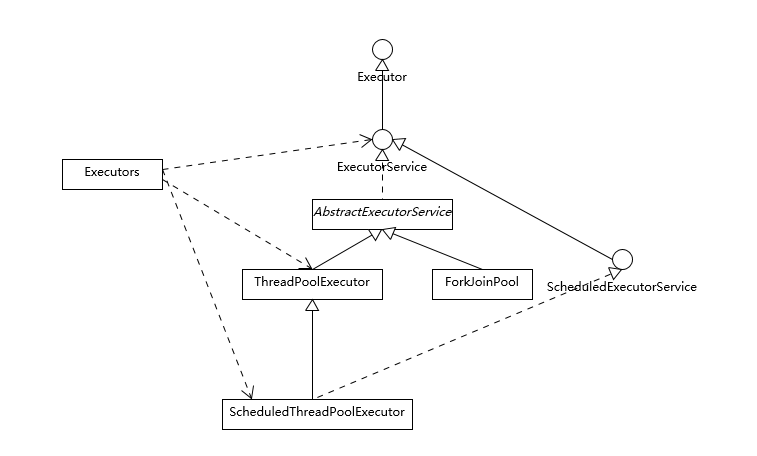
- 首先,我们来看看 Executor 框架的基本组成,请参考下面的类图。
image
- 我们从整体上把握一下各个类型的主要设计目的:
- Executor 是一个基础的接口,其初衷是将任务提交和任务执行细节解耦,这一点可以体会其定义的唯一方法。
void execute(Runnable command); - Executor 的设计是源于 Java 早期线程 API 使用的教训,开发者在实现应用逻辑时,被太多线程创建、调度等不相关细节所打扰。就像我们进行 HTTP 通信,如果还需要自己操作 TCP 握手,开发效率低下,质量也难以保证。
- ExecutorService 则更加完善,不仅提供 service 的管理功能,比如 shutdown 等方法,也提供了更加全面的提交任务机制,如返回Future而不是 void 的 submit 方法。
<T> Future<T> submit(Callable<T> task); - 注意,这个例子输入的可是Callable,它解决了 Runnable 无法返回结果的困扰。
- Java 标准类库提供了几种基础实现,比如ThreadPoolExecutor、ScheduledThreadPoolExecutor、ForkJoinPool。这些线程池的设计特点在于其高度的可调节性和灵活性,以尽量满足复杂多变的实际应用场景,我会进一步分析其构建部分的源码,剖析这种灵活性的源头。
- Executors 则从简化使用的角度,为我们提供了各种方便的静态工厂方法。
- 下面我就从源码角度,分析线程池的设计与实现,我将主要围绕最基础的 ThreadPoolExecutor 源码。ScheduledThreadPoolExecutor 是 ThreadPoolExecutor 的扩展,主要是增加了调度逻辑,如想深入了解,你可以参考相关教程。而 ForkJoinPool 则是为 ForkJoinTask 定制的线程池,与通常意义的线程池有所不同。
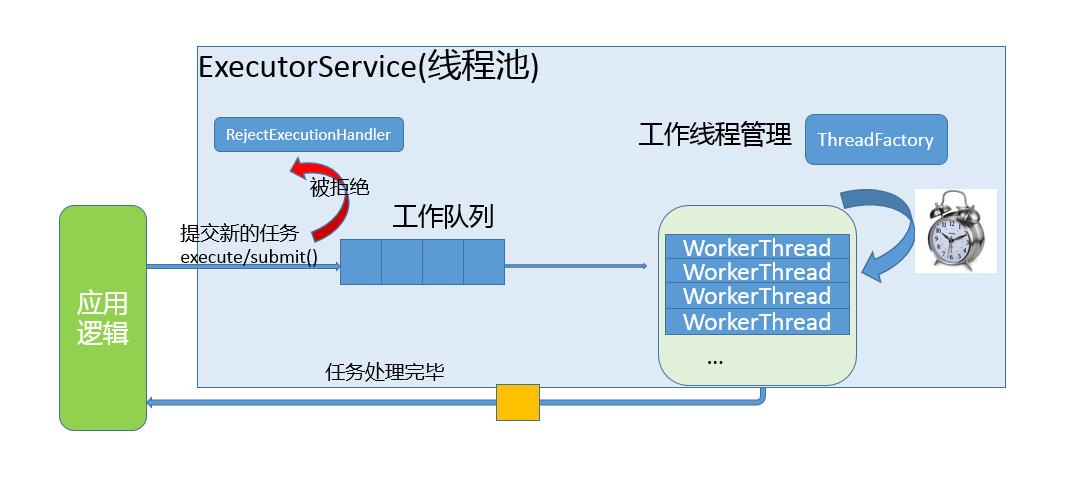
- 这部分内容比较晦涩,罗列概念也不利于你去理解,所以我会配合一些示意图来说明。在现实应用中,理解应用与线程池的交互和线程池的内部工作过程,你可以参考下图。
image
- 简单理解一下:
- 工作队列负责存储用户提交的各个任务,这个工作队列,可以是容量为 0 的 SynchronousQueue(使用 newCachedThreadPool),也可以是像固定大小线程池(newFixedThreadPool)那样使用 LinkedBlockingQueue。
private final BlockingQueue<Runnable> workQueue;- 内部的“线程池”,这是指保持工作线程的集合,线程池需要在运行过程中管理线程创建、销毁。例如,对于带缓存的线程池,当任务压力较大时,线程池会创建新的工作线程;当业务压力退去,线程池会在闲置一段时间(默认 60 秒)后结束线程。
private final HashSet<Worker> workers = new HashSet<>(); - 线程池的工作线程被抽象为静态内部类 Worker,基于AQS实现。
- ThreadFactory 提供上面所需要的创建线程逻辑。
- 如果任务提交时被拒绝,比如线程池已经处于 SHUTDOWN 状态,需要为其提供处理逻辑,Java 标准库提供了类似ThreadPoolExecutor.AbortPolicy等默认实现,也可以按照实际需求自定义。
- 从上面的分析,就可以看出线程池的几个基本组成部分,一起都体现在线程池的构造函数中,从字面我们就可以大概猜测到其用意:
- corePoolSize,所谓的核心线程数,可以大致理解为长期驻留的线程数目(除非设置了 allowCoreThreadTimeOut)。对于不同的线程池,这个值可能会有很大区别,比如 newFixedThreadPool 会将其设置为 nThreads,而对于 newCachedThreadPool 则是为 0。
- maximumPoolSize,顾名思义,就是线程不够时能够创建的最大线程数。同样进行对比,对于 newFixedThreadPool,当然就是 nThreads,因为其要求是固定大小,而 newCachedThreadPool 则是 Integer.MAX_VALUE。
- keepAliveTime 和 TimeUnit,这两个参数指定了额外的线程能够闲置多久,显然有些线程池不需要它。
- workQueue,工作队列,必须是 BlockingQueue。
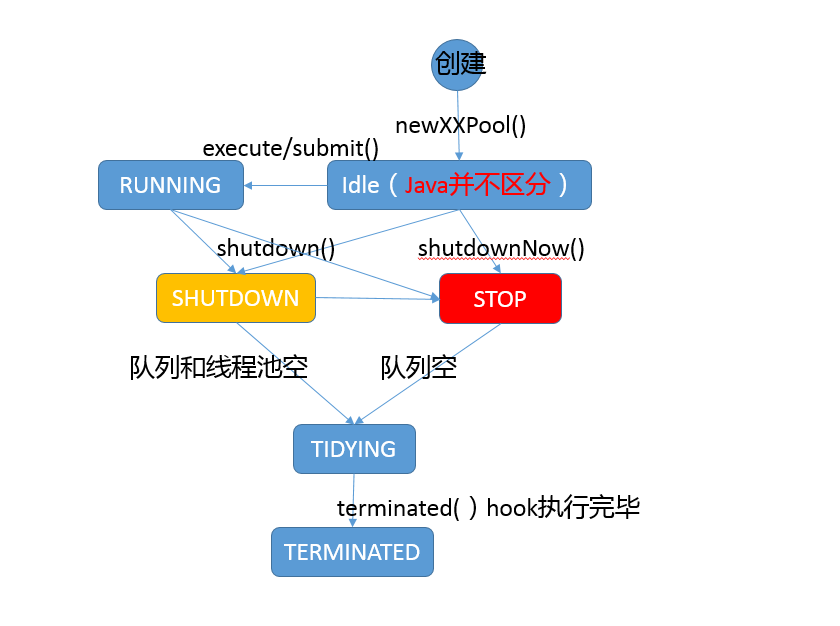
05.线程池状态
- 进一步分析,线程池既然有生命周期,它的状态是如何表征的呢?
- 这里有一个非常有意思的设计,ctl变量被赋予了双重角色,通过高低位的不同,既表示线程池状态,又表示工作线程数目,这是一个典型的高效优化。试想,实际系统中,虽然我们可以指定线程极限为Integer.MAX_VALUE,但是因为资源限制,这只是个理论值,所以完全可以将空闲位赋予其他意义。
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); // 真正决定了工作线程数的理论上限 private static final int COUNT_BITS = Integer.SIZE - 3; private static final int COUNT_MASK = (1 << COUNT_BITS) - 1; // 线程池状态,存储在数字的高位 private static final int RUNNING = -1 << COUNT_BITS; … // Packing and unpacking ctl private static int runStateOf(int c) { return c & ~COUNT_MASK; } private static int workerCountOf(int c) { return c & COUNT_MASK; } private static int ctlOf(int rs, int wc) { return rs | wc; } - 为了让你能对线程生命周期有个更加清晰的印象,我这里画了一个简单的状态流转图,对线程池的可能状态和其内部方法之间进行了对应,如果有不理解的方法,请参考 Javadoc。注意,实际 Java 代码中并不存在所谓 Idle 状态,我添加它仅仅是便于理解。
image
- 前面都是对线程池属性和构建等方面的分析,下面我选择典型的 execute 方法,来看看其是如何工作的,具体逻辑请参考我添加的注释,配合代码更加容易理解。
public void execute(Runnable command) { … int c = ctl.get(); // 检查工作线程数目,低于corePoolSize则添加Worker if (workerCountOf(c) < corePoolSize) { if (addWorker(command, true)) return; c = ctl.get(); } // isRunning就是检查线程池是否被shutdown // 工作队列可能是有界的,offer是比较友好的入队方式 if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); // 再次进行防御性检查 if (! isRunning(recheck) && remove(command)) reject(command); else if (workerCountOf(recheck) == 0) addWorker(null, false); } // 尝试添加一个worker,如果失败意味着已经饱和或者被shutdown了 else if (!addWorker(command, false)) reject(command); }
其他介绍
- 深入Java线程池:从设计思想到源码解读
- https://blog.csdn.net/qq_31587111/article/details/122731855
- Java线程池实现原理及其在美团业务中的实践
- https://tech.meituan.com/2020/04/02/java-pooling-pratice-in-meituan.html