05.栈设计思想和原理
目录介绍
- 01.先看一道思考题
- 02.如何实现该功能
- 03.如何理解栈
- 04.如何实现一个栈
- 05.动态扩容顺序栈
- 06.栈的时间复杂度
- 07.栈在函数中场景
- 08.栈实现的浏览器
01.先看一道思考题
- 浏览器的前进、后退功能
- 当你依次访问完一串页面 a-b-c 之后,点击浏览器的后退按钮,就可以查看之前浏览过的页面 b 和 a。当你后退到页面 a,点击前进按钮,就可以重新查看页面 b 和 c。
- 但是,如果你后退到页面 b 后,点击了新的页面 d,那就无法再通过前进、后退功能查看页面 c 了。
02.如何实现该功能
- 假设你是 Chrome 浏览器的开发工程师,你会如何实现这个功能呢?
- 这就要用到我们今天要讲的“栈”这种数据结构。
03.如何理解栈
- 关于“栈”,一个非常贴切的例子,就是一摞叠在一起的盘子。
- 平时放盘子的时候,都是从下往上一个一个放;取的时候,我们也是从上往下一个一个地依次取,不能从中间任意抽出。
- 后进者先出,先进者后出,这就是典型的“栈”结构。
- 从栈的操作特性上来看
- 栈是一种“操作受限”的线性表,只允许在一端插入和删除数据。
- 为何要使用链表
- 相比数组和链表,栈带给我的只有限制,并没有任何优势。那我直接使用数组或者链表不就好了吗?为什么还要用这个“操作受限”的“栈”呢?
- 特定的数据结构是对特定场景的抽象,而且,数组或链表暴露了太多的操作接口,操作上的确灵活自由,但使用时就比较不可控,自然也就更容易出错。
- 当某个数据集合只涉及在一端插入和删除数据,并且满足后进先出、先进后出的特性,这时我们就应该首选“栈”这种数据结构。
- 使用场景
- WebView页面打开和关闭管理;浏览器前进和后退功能;Activity任务栈管理。
04.如何实现一个栈
- 栈主要包含两个操作
- 入栈和出栈,也就是在栈顶插入一个数据和从栈顶删除一个数据。
- 栈如何实现
- 栈既可以用数组来实现,也可以用链表来实现。用数组实现的栈,我们叫作顺序栈,用链表实现的栈,我们叫作链式栈。
- 它的操作的时间、空间复杂度是多少呢?
- 不管是顺序栈还是链式栈,我们存储数据只需要一个大小为 n 的数组就够了。在入栈和出栈过程中,只需要一两个临时变量存储空间,所以空间复杂度是 O(1)。
- 空间复杂度分析是不是很简单?时间复杂度也不难。不管是顺序栈还是链式栈,入栈、出栈只涉及栈顶个别数据的操作,所以时间复杂度都是 O(1)。
05.动态扩容顺序栈
- 如何基于数组实现一个可以支持动态扩容的栈呢?
- 当数组空间不够时,我们就重新申请一块更大的内存,将原来数组中数据统统拷贝过去。这样就实现了一个支持动态扩容的数组。
- 如果要实现一个支持动态扩容的栈,只需要底层依赖一个支持动态扩容的数组就可以了。当栈满了之后,就申请一个更大的数组,将原来的数据搬移到新数组中。
06.栈的时间复杂度
- 分析一下支持动态扩容的顺序栈的入栈、出栈操作的时间复杂度。
- 对于出栈操作来说,我们不会涉及内存的重新申请和数据的搬移,所以出栈的时间复杂度仍然是 O(1)。
- 对于入栈操作来说,当栈中有空闲空间时,入栈操作的时间复杂度为 O(1)。但当空间不够时,就需要重新申请内存和数据搬移,所以时间复杂度就变成了 O(n)。
- 如何计算入栈的平均复杂度
- 对于入栈操作来说,最好情况时间复杂度是 O(1),最坏情况时间复杂度是 O(n)。那平均情况下的时间复杂度又是多少呢?
- 还记得我们在复杂度分析那一节中讲的摊还分析法吗?这个入栈操作的平均情况下的时间复杂度可以用摊还分析法来分析。
07.栈在函数中场景
- 经典的一个应用场景就是函数调用栈
- 操作系统给每个线程分配了一块独立的内存空间,这块内存被组织成“栈”这种结构, 用来存储函数调用时的临时变量。
- 每进入一个函数,就会将临时变量作为一个栈帧入栈,当被调用函数执行完成,返回之后,将这个函数对应的栈帧出栈。
- 来看下这段代码的执行过程
int main() { int a = 1; int ret = 0; int res = 0; ret = add(3, 5); res = a + ret; printf("%d", res); reuturn 0; } int add(int x, int y) { int sum = 0; sum = x + y; return sum; }- 从代码中我们可以看出,main() 函数调用了 add() 函数,获取计算结果,并且与临时变量 a 相加,最后打印 res 的值。
- 为了让你清晰地看到这个过程对应的函数栈里出栈、入栈的操作,我画了一张图。图中显示的是,在执行到 add() 函数时,函数调用栈的情况。

image
08.栈实现的浏览器
- 如何实现浏览器的前进、后退功能?
- 其实,用两个栈就可以非常完美地解决这个问题。
- 使用两个栈实现浏览器前进和后退
- 使用两个栈,X 和 Y,我们把首次浏览的页面依次压入栈 X,当点击后退按钮时,再依次从栈X 中出栈,并将出栈的数据依次放入栈 Y。
- 当我们点击前进按钮时,我们依次从栈 Y 中取出数据,放入栈 X 中。当栈 X 中没有数据时,那就说明没有页面可以继续后退浏览了。
- 当栈 Y 中没有数据,那就说明没有页面可以点击前进按钮浏览了。
- 查看页面的操作
- 比如你顺序查看了 a,b,c 三个页面,我们就依次把 a,b,c 压入栈,这个时候,两个栈的数据就是这个样子:
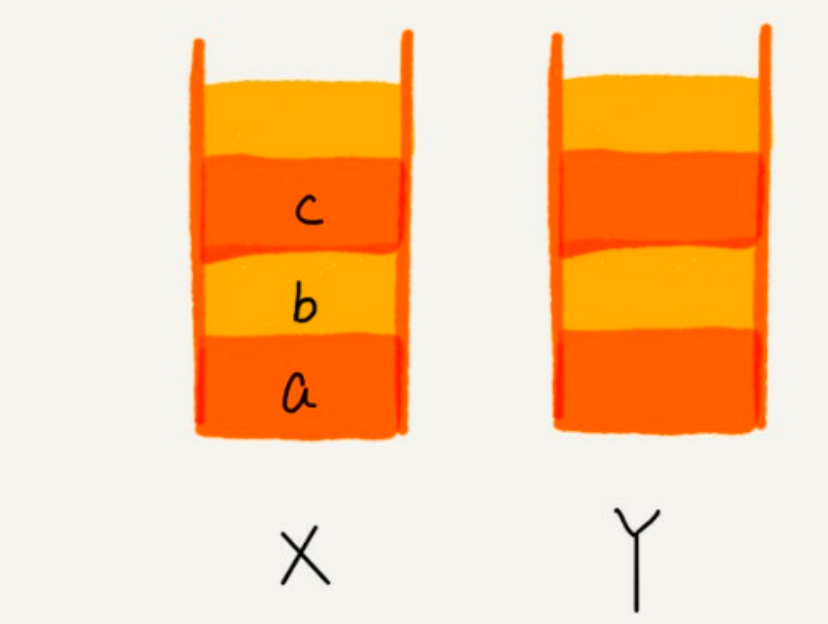
image - 当你通过浏览器的后退按钮,从页面 c 后退到页面 a 之后,我们就依次把 c 和 b 从栈 X 中弹出,并且依次放入到栈 Y。这个时候,两个栈的数据就是这个样子:
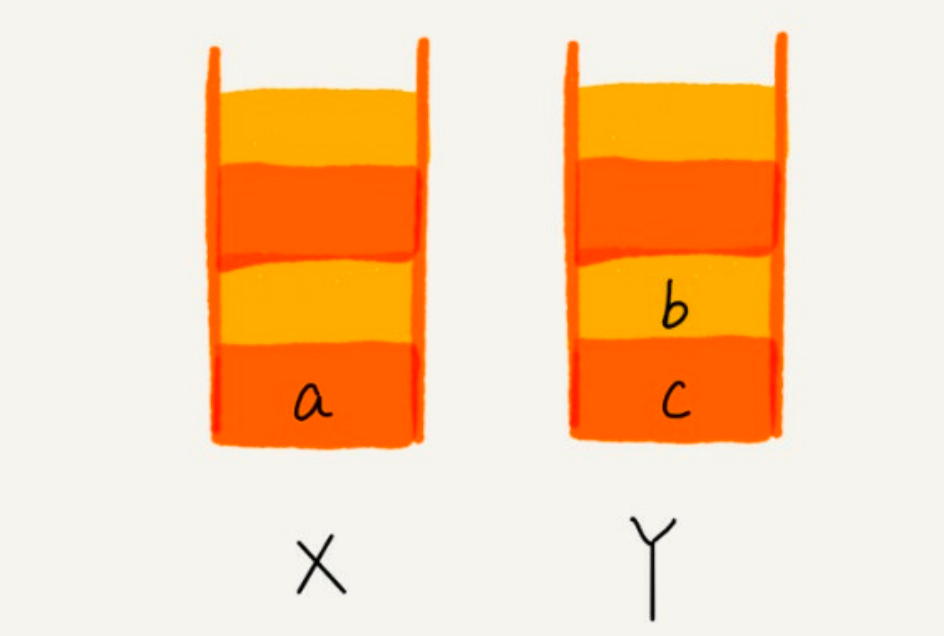
image - 这个时候你又想看页面 b,于是你又点击前进按钮回到 b 页面,我们就把 b 再从栈 Y 中出栈,放入栈 X 中。此时两个栈的数据是这个样子:
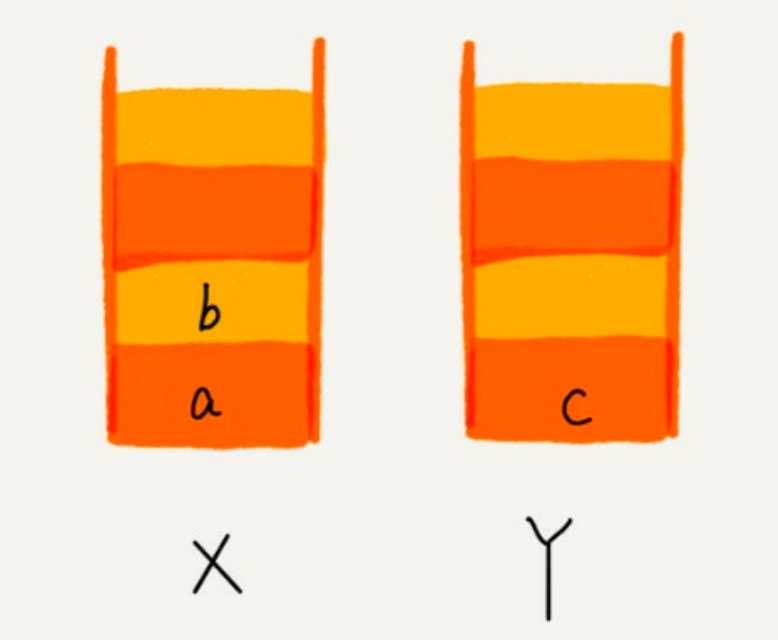
image - 这个时候,你通过页面 b 又跳转到新的页面 d 了,页面 c 就无法再通过前进、后退按钮重复查看了,所以需要清空栈 Y。此时两个栈的数据这个样子:
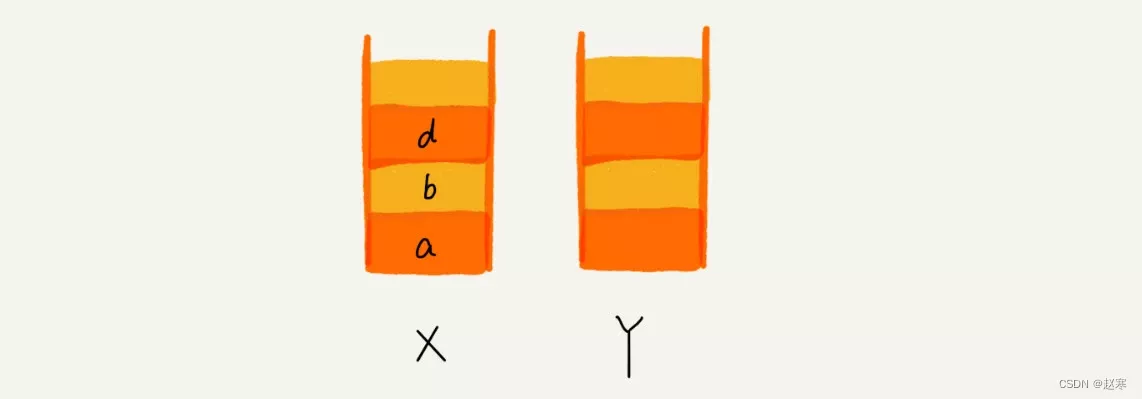
image